




Manual
do
Maker
.
com
Quarentena Maker - Dia 6: Ler código de barras em arquivos de imagem



Nunca vi alguém viciado em pagar boletos; quanto antes me livro deles, melhor. Só que alguns não são realmente PDF, são montados a partir de imagem, e ler o código de barras com o smartphone "mirando" na tela do computador pode ser uma missão impossível. Por isso veremos nesse artigo como ler código de barras em arquivos de imagem também.
Qual PDF é melhor? O "original" ou o composto por imagens?
Quando se trata de boletos, a melhor opção é o arquivo gerado a partir de imagens. Isso porque existe a possibilidade de alteração do conteúdo do PDF, permitindo que (por exemplo) os números do boleto sejam modificados. Para quem "escaneia" o código de barras não é tão impactante, mas para quem digita os números, uma transferência para uma conta desconhecida pode ser o resultado.
Quando o arquivo PDF é gerado na estrutura padrão, tende a ser um arquivo de tamanho reduzido (exceto se composto por texto e imagem, o que pode fazê-lo ser maior que o anteriormente citado).
Como identificar um boleto falso visualmente?
Alguns cuidados podem ser tomados para evitar cair em uma fraude. Tenha em mente que o código de barras é o facilitador do boleto para poupar o cliente de digitar todos os números. Logo, o número deve corresponder ao código de barras. Alguns pontos importantes desse número podem ser identificados nos campos descritos na estrutura em tabelas do boleto. Veja essa imagem de um boleto do Bradesco:


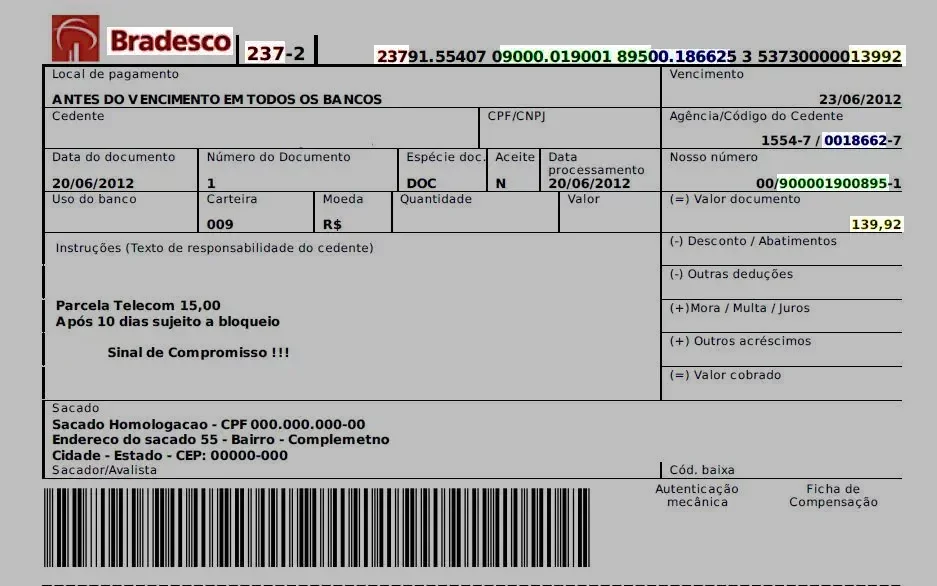
Olhe primeiramente para o banco. O número do banco pode ser consultado no Google ou na sua própria conta, caso seja também seu banco. Outra forma de identificar esse campo é abrindo o aplicativo do seu banco e simulando uma transferência. Ao selecionar o banco, deve aparecer o número.
Campos do boleto
Os códigos de barras dos boletos contêm de 44 à 48 dígitos, separados em 5 campos:
- Os três primeiros dígitos devem corresponder ao número do banco.
- O quarto dígito identifica o tipo de moeda, sendo 9 para nacional e 0 para outras moedas.
- Os últimos 10 dígitos são referentes ao valor.
- Os números finais de cada sequência são os dígitos verificadores, não se assuste porque esse número quebra a sequência.
- Os quatro números que precedem os 10 dígitos do valor são a data de vencimento em um "pseudo-timestamp", que é o inicio da base de dados até a data de vencimento. Se esses números forem "0000", não tem data de vencimento.
- As demais correspondências estão em suas respectivas cores, é auto-explicativo.
Especificações técnicas do código de barras
Se desejar ter detalhes técnicos da composição do boleto (que podem variar conforme o banco, mas sempre contendo os supracitados), o Banco do Brasil fornece as especificações para criar seu boleto.



Sabendo todos esses detalhes, podemos utilizar um conjunto de isolamento de área e um programa de OCR para comparar o número descrito no boleto com o número do código de barras. Não seria mal, hum? Mas nesse artigo vamos focar em ler código de barras em arquivos de imagens.
Ler código de barras em arquivos de imagem
Para esse processo, precisamos ter em mente que:
- O arquivo original contém alguma estrutura PDF, não podemos tratá-lo diretamente como imagem.
- Sendo um arquivo com estrutura PDF, precisaremos fazer a leitura a partir da imagem, e devemos converter o PDF para um formato legível, como JPG ou PNG.
- O PDF pode conter várias páginas. Nesse momento não faremos a automação do processo, mas já aproveitarei para descrever alguns dos recursos que serão utilizados para esse fim.
Instalando as dependências
Todo o processo eu faço no Linux. Se estiver utilizando Windows, instale o subsistema Linux, que lhe dará acesso ao shell bash. Outra opção é fazer uma máquina virtual utilizando, por exemplo, o VirtualBox.
Siga os seguintes passos (em qualquer distribuição Linux baseada em Debian, como Ubuntu, Raspbian, Emdebian etc):
sudo apt-get install libzbar0
sudo pip install pyzbar
sudo pip install opencv-utils opencv-python
sudo apt-get install qpdf
sudo apt-get install poppler-utils
Instaladas as dependências, teremos entre todos os recursos disponíveis as opções:
Extrair uma página do PDF
Podemos definir qual página do arquivo PDF extrairemos, passando o arquivo de entrada e o arquivo de destino:
qpdf --empty --pages pdf_with_pages.pdf 1 -- page1.pdf
Converter PDF para jpg
Podemos converter a página extraída para imagem agora:
pdftoppm -jpeg page1.pdf page1.jpg
Descobrir o número de páginas de um arquivo PDF
Podemos descobrir previamente o número de páginas para automatizar o processo de extração e conversão:
Descobrir numero de paginas do pdf:
pdfinfo d.pdf |egrep -i '^pages:'|awk {'print $NF'}
Ler código de barras em arquivos de imagem utilizando python com pyzbar
Por essa razão temos algumas dependências instaladas através do pip. Hora de criar um script python que utilizará visão computacional para "ver" o arquivo que será passado ao pyzbar. Nomeie como deseja. No meu caso, chamei de "scan.py":
#!/usr/bin/env python
# import the necessary packages
from pyzbar import pyzbar
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# load the input image
image = cv2.imread(args["image"])
# find the barcodes in the image and decode each of the barcodes
barcodes = pyzbar.decode(image)
# loop over the detected barcodes
for barcode in barcodes:
# extract the bounding box location of the barcode and draw the
# bounding box surrounding the barcode on the image
(x, y, w, h) = barcode.rect
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
# the barcode data is a bytes object so if we want to draw it on
# our output image we need to convert it to a string first
barcodeData = barcode.data.decode("utf-8")
barcodeType = barcode.type
# draw the barcode data and barcode type on the image
text = "{} ({})".format(barcodeData, barcodeType)
cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 0, 255), 2)
# print the barcode type and data to the terminal
print("[INFO] Found {} barcode: {}".format(barcodeType, barcodeData))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
Esse script é baseado no PyImageSearch, recomendo fortemente para quem não tiver dificuldade com o idioma inglês. O site trata profundamente de visão computacional com OpenCV, dlib e afins.
Quando executar o script, ele lerá a imagem passada e abrirá no visualizador. Para fechar, pressione 'q'. Se fechar no 'X' da janela, o processo ficará travado em segundo plano.
chmod 700 scan.py
./scan.py --image page1.jpg
Já escrevi sobre leitura de código de barras e QR Code com Raspberry nesse outro artigo, aproveite pra dar uma conferida.
Revisão: Ricardo Amaral de Andrade



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.