




Manual
do
Maker
.
com
Delimitador com OpenCV e primeiro passo com OCR



Delimitador com OpenCV
Em breve pretendo escrever um artigo que envolve bastante conceitos com OpenCV e OCR. Hoje fiz minha primeira pesquisa a respeito do que necessito e já achei alguns recursos que são interessantes também para outros propósitos. De imediato, eu queria isolar textos, apesar de que essa técnica não serve só pra isso. Por exemplo, eu tenho um cartão de visita e quero isolar os blocos de dados para depois ler os textos ou fazer bluring, ou algo que seja, por isso esse artigo sobre delimitador com OpenCV . Utilizei esse modelo (antes e depois):


Nessa pequena porção de código utilizado para esse propósito já é possível pensar na possibilidade de decomposição da imagem, uma vez que você tem os boxes, pode copiá-los para novas imagens ou por exemplo, aplicar um blur em determinada região da imagem.
Por alguma razão, em uma imagem png do logo do Linux o resultado ficou estranho, provavelmente pela conversão. O antes e o depois:


Na parte de OCR será necessário um trabalho bem mais amplo porque o resultado final depende de validação, aí entra inteligência artificial. Mas, se for para transformar algo em texto e depois corrigir os erros, você pode usar o Tesserac:


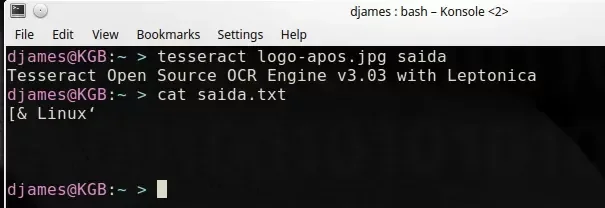
Parece que o tesseract tentou "desenhar" o pinguim, eu gostei :)
Claro que para fazer um reconhecimento de placa não é elegante ficar chamando programas no shell, mas dessa vez foi apenas uma dica, o projeto é mesmo fazer o LPR (Licence Plate Recognition) e já tenho todos os componentes necessários para fazê-lo com a devida qualidade.
Pra finalizar esse post simplório, o código para esse delimitador:
import cv2
import sys
if not sys.argv[1]:
exit(0)
#eh uma convencao a imagem principal chamar image e o quadro de video
#chamar frame, entao sigamos o padrao
image = cv2.imread(sys.argv[1])
#a coversao para gray, diminuindo assim o numero de camadas porque
#cada pixel tem informacoes de B,G,R e convertendo para grayscale
#o processamento sera menor e mais preciso
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#gatilho
n,thresh = cv2.threshold(gray,150,255,cv2.THRESH_BINARY_INV)
#o kernel pode ser feito de diversar maneiras
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(3,3))
#dilatar
dilated = cv2.dilate(thresh,kernel,iterations = 13)
contours, harch = cv2.findContours(dilated,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
# agora a imagem original recebe um retangulo em cada area encontrada
for contour in contours:
[x,y,w,h] = cv2.boundingRect(contour)
if h>250 and w>250:
continue
if h<40 or w<40:
continue
cv2.rectangle(image,(x,y),(x+w,y+h),(255,0,255),2)
# depois de tracar o retangulo na imagem acima, salva para o disco
img_name = sys.argv[1][:-4] + "-new.jpg"
cv2.imwrite(img_name, image)
Enfatizo que não há nada de especial nesse código, mas será bastante útil em breve. Parte dele encontrei no stackoverflow e achei útil, por isso implementei assim.
Recomendo a leitura do reconhecimento facial utilizando rede neural.
Inscreva-se no nosso canal Manual do Maker Brasil no YouTube.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.