




Manual
do
Maker
.
com
Como salvar um model treinado com Keras



Vimos como fazer uma ANN, depois vimos como fazer uma CNN. É incrível e, apesar dos conceitos necessários, não é uma coisa de outro mundo utilizar um conjunto de dados para treinar uma rede neural. O chato é ter que fazer o treinamento toda a vez que for executar o programa, tendo que deixar o programa rodando para sempre para não perder o treinamento, certo? - Errado!
Após fazer o treinamento de um dataset, a estrutura necessária já existirá na memória enquanto o programa estiver rodando, então podemos salvar esse treinamento e carregá-lo sempre que for necessário utilizá-lo novamente, dispensando um novo treinamento! Vamos ver como?
Faça o download de um dataset
Para esse exemplo, vamos utilizar a base de dados Pima Indians Diabetes, para fazer predição do risco de diabetes baseado em fatores como gravidez, BMI, nível de insulina, idade etc.
Eu peguei o dataset nesse repositório do Github.
Treinamento de um dataset
O procedimento é o mesmo que utilizamos para fazer a classificação de vinho. A primeira parte portanto fica desse jeito:
from keras.models import Sequential
from keras.layers import Dense
from keras.models import model_from_json
import numpy
import os
# fix random seed for reproducibility
numpy.random.seed(7)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, Y, epochs=150, batch_size=10, verbose=0)
# evaluate the model
scores = model.evaluate(X, Y, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
O treinamento foi feito em alguns poucos segundos na GPU (gtx1050), é um dataset modesto. A acurácia aqui deu 80.47%, me pareceu bastante bom.
Salvar um model de rede neural em JSON
Com Keras é possível descrever qualquer model usando o formato JSON, chamando a função:
.to\_json()
Pode-se salvá-lo em um arquivo e posteriormente carregá-lo via:
model\_from\_json()
Os pesos são salvos diretamente do modelo usando:
save\_weights()
e depois pode ser carregado usando:
load\_weights()
Como mostrado nos artigos anteriores, o exemplo acima faz o treino e predição de um dataset. Agora vamos incrementar um pouco, salvando nosso model e pesos, então carregá-lo do computador. Esse processo deve ser feito sempre depois de:
model.fit()
quando a classificação já foi preparada. Seguindo:
# serialize model to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model.h5")
print("Saved model to disk")
Depois para carregar:
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("model.h5")
print("Loaded model from disk")
# evaluate loaded model on test data
loaded_model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
score = loaded_model.evaluate(X, Y, verbose=0)
print("%s: %.2f%%" % (loaded_model.metrics_names[1], score[1]*100))
Ou seja, se quisermos carregar o model salvo invés de fazer novamente um treinamento, o programa completo seria:
from keras.models import Sequential
from keras.layers import Dense
from keras.models import model_from_json
import numpy
import os
# fix random seed for reproducibility
numpy.random.seed(7)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("model.h5")
print("Loaded model from disk")
# evaluate loaded model on test data
loaded_model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
score = loaded_model.evaluate(X, Y, verbose=0)
print("%s: %.2f%%" % (loaded_model.metrics_names[1], score[1]*100))
Essa imagem abaixo mostra a carga e execução do peso.


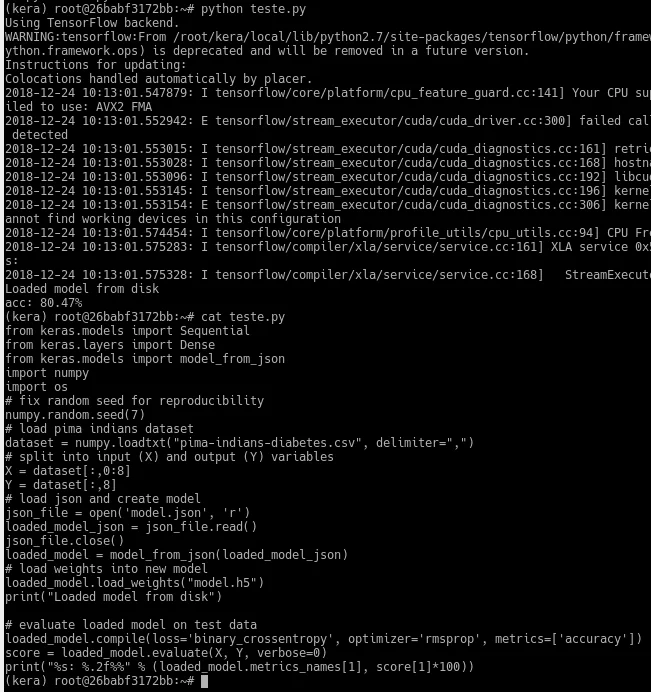
Eu não sei a razão, mas carregando os pesos apenas deu uma diferença na acurácia, ficando em 77,08%. Tem a possibilidade de salvar o model inteiro, complementarei em outro artigo. Agora vou escrever mais um artigo que tenho em mente e acredito que seja do interesse de muitos.
Se gostou, curta a página Manual do Maker no facebook, clicando alí em cima na coluna da direita. Siga-nos também no Youtube, no canal DobitAoByte, se inscreva e clique no sininho para receber notificações.
Até a próxima!



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.