




Manual
do
Maker
.
com
Convolutional Neural Network com Keras



Nos últimos dois artigos discorri sobre perceptrons multicamada, um tipo de rede neural utilizado para fazer classificação. Ainda farei outros artigos relacionados, como prometido, mas resolvi escrever agora sobre outro tipo de rede neural; a CNN ou, Convolutional Neural Network.
Esse tipo de rede de aprendizado profundo é utilizado amplamente no campo de imagens, em áreas como medicina, reconhecimento de pessoas e objetos, animais OCR etc. Hoje vamos ver a utilização de Keras com um dataset bastante conhecido já, o MNIST, utilizado para fazer reconhecimento de caracteres numéricos escritos à mão.
Convolutional Neural Network com keras
Enquanto em perceptrons multicamada utiliza-se dados lineares (arrays), em CNNs se utiliza matrizes bidimensionais, tridimensionais ou até multidimensionais. Obviamente o processamento desse tipo de rede é mais complexo, mas fazer um treinamento com o desse artigo não é uma tarefa árdua, desde que já tenha preparado o ambiente para sua utilização em nossos testes de laboratório.
MNIST
Eu tenho a impressão de que esse dataset é o mais popular que existe, e não é pra menos. Não é uma das aplicações mais incríveis de rede neural?
O MNIST é um dataset com 70 mil imagens de escrita à mão, além de dígitos de 0 a 9. Faremos o reconhecimento utilizando uma CNN com Keras.
Dessas 70 mil imagens, 60 mil são ara o treinamento e 10 mil para teste.
Carregando o dataset
Lembra quando citei que acreditava ser um dos dataset mais populares? Uma das razões para eu acreditar nisso é o fato de que ele está contido na própria biblioteca Keras; tudo arranjadinho para uso. Então, vamos usá-lo!
Comece carregando o datset:
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
A segunda linha faz o download das imagens automaticamente.


Análise exploratória dos dados
Vamos observar uma das imagens do dataset para ver com o que estamos mexendo. Entre no virtualenv criado no artigo anterior (se perdeu, leia, execute e depois volte para cá). Para isso, fazemos:
import matplotlib.pyplot as plt
plt.imshow(X_train[0]) # pega a primeira imagem
Se não tiver o matlotlib instalado, instale-o com o pip. Sendo esse o caso, há de se instalar também o python-tk:
sudo su
pip install matplotlib
apt-get install python-tk
O grande problema aqui é que se você estiver rodando de dentro de um container docker, não será possível ver a imagem. Nem vou citar tudo o que tem que fazer porque é trabalhoso, só abandone a ideia ou teste no computador nativo, já que não é fundamental para o nosso treinamento que seja feito no ambiente de desenvolvimento. De qualquer modo, o que seria visto é isso:
INFELIZMENTE ESSA IMAGEM FOI PERDIDA
As dimensões podem ser vistas com a linha:
X_train[0].shape
Estou fazendo tudo no bpython para explicar esse artigo. Mais uma vez recomendo a leitura do artigo sobre a preparação do ambiente.
As imagens serem do mesmo tamanho é fundamental. Não dá pra fazer um treinamento com imagens de tamanhos variados, é necessário que a matriz de dados tenha coerência. É mais ou menos o que foi explicado nesse artigo sobre a consistência dos dados.
Como se trata de um dataset criado para o propósito de treinamento, não precisaremos nos preocupar com dimensões ou tamanho de imagem, mas para saber, quanto menor for a imagem, melhor. Lembre-se de que a rede neural deverá validar cada pixel da imagem. Essas imagens do MNIST tem a dimensão de 28x28 pixels e estão em escala de cinza, ou seja, possuem apenas uma camada de dados.
Formatar os dados para treinamento e teste
Precisamos definir a estrutura de treino e de testes da rede neural. Ela precisará treinar e testar os dados. Fazemos isso em duas linhas, definindo-as em X\_train e X\_test.
X_train = X_train.reshape(60000,28,28,1)
X_test = X_test.reshape(10000,28,28,1)
A função reshape define o número de imagens a alocar, além de sua dimensão.
Precisamos criar uma matriz binária e uma categoria para os dados:
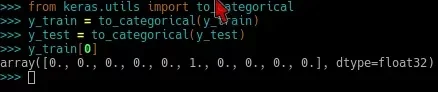
from keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_train[0]
A última linha exibirá dados da matriz criada. Ela retorna algo como:


Construção do model
Mais uma vez, utilizaremos o model Sequential. Adicionaremos uma camada com 64 nós, a ativação será novamente ReLU e as dimensões são 28x28 em grayscale, portanto, só tem uma camada na imagem, parâmetro passado como '1'.
A grande diferença aqui é a conversão bidimensional e a última ativação; dessa vez, softmax.
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten
model = Sequential()
model.add(Conv2D(64, kernel_size=3, activation='relu', input_shape=(28,28,1)))
model.add(Conv2D(32, kernel_size=3, activation='relu'))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
O parâmetro 64 e 32 da primeira e segunda linha da adição no model se referem ao número de nós em cada camada, como explicado no artigo anterior. Esses números podem variar, mas parece que esses valores tem sido usados por convenção.
O kernel\_size é o tamanho do filtro para a convolução. É como se estivessemos passando uma lupa sobre uma página para dar o zoom; a região sob a lente seria o kernel_size. Nas linhas acima, o tamanho 3 define uma matrix de 3x3.
Entre as camadas conv2D e Dense, temos uma camada Flatten. Ela será uma conexão entre a convolução e as camadas densas.
A camada Dense é usada como camada de saída, com 10 nós, sendo uma para cada número possível. A utilização de softmax como ativação de saída gerará o resultado de uma somatória que pode ir até 1, para fazer a predição baseada na maior probabilidade.
Compilar o model
Até aqui você deve ter reparado que as mudanças para uma rede perceptron multicamadas tem pouca diferença. Seguimos quase os mesmos passos e agora estamos prontos para a compilação do model. Como a compilação tem o mesmo formato, não vou discorrer a respeito, na esperança que lhe desperte interesse em ler os últimos dois artigos que precedem este.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Treinar o model
Da mesma forma, o treinamento é como descrito no artigo anterior, mas dessa vez o epoch é bem menor. Trabalhar sobre 70 mil imagens de 28x28 pixels não é tão simples quanto um array de dados formatados, hum?
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3)
Peguei um pedaço aleatório do treinamento porque passou rápido demais quando iniciei o processo:


Fazendo predição com o MNIST treinado
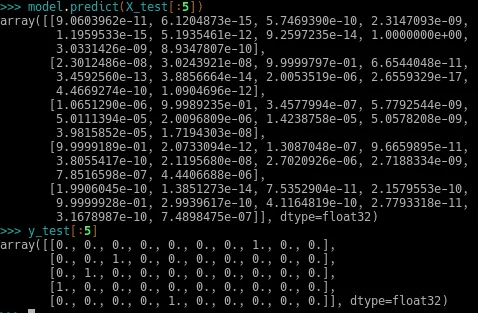
Claro que o intuito não é só gastar energia. Agora é hora de brincar com nossa rede. A função de predição para teste nos dará um array com 10 números, sendo as probabilidades que uma imagem de entrada representa para cada dígito. Se você tiver uma imagem para entrada, poderá passá-la para a predição, ou então testar com imagens do próprio dataset.
A predição deve ser 01, que é o sufixo do número contido em cada posição do array, como resultado da somatória. O retorno da predição são arrays de 10 posições, representando os números de 0 a 9. Passei a predição dos 5 primeiros números do array, que seriam os dígitos 7, 2, 1, 0, 4. Todos bateram perfeitamente e o primeiro deu 100%! Wow!
O último array é a posição numérica, de 0 a 9. Onde estiver '1', trata-se do respectivo valor posicional.


Ainda faremos outras brincadeiras em breve. Caso esteja procurando por reconhecimento facial, dê uma pesquisada no google por "OpenFace dobitaobyte" ou digite na caixa de pesquisa aí em cima. Tem algumas coisas com TensorFlow, Caffe, Keras e Theano também, divirta-se!
Código completo
O código completo ficou desse jeito:
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000,28,28,1)
X_test = X_test.reshape(10000,28,28,1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
model = Sequential()
#add model layers
model.add(Conv2D(64, kernel_size=3, activation=’relu’, input_shape=(28,28,1)))
model.add(Conv2D(32, kernel_size=3, activation=’relu’))
model.add(Flatten())
model.add(Dense(10, activation=’softmax’))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3)
model.predict(X_test[:5])
y_test[:5]
Espero que tenha gostado. Curta a página Manual do Maker no Facebook, clicando ali em cima na coluna da direita. Também temos nosso canal no Youtube, se inscreva, e clique no sininho para receber notificação de vídeo novo.
Até a próxima!



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.