




Manual
do
Maker
.
com
Como criar um dataset para deep learning?



É bastante prático e divertido utilizar datasets e models prontos para brincar em casa. Claro que, conforme formos avançando com redes neurais, quereremos criar nossas próprias fontes de dados para treinamento. Aí vem a questão: Como criar um dataset para deep learning? Esse foi meu aprendizado mais importante dessa semana e o artigo me servirá para rememoração até pegar o jeito.
Um conjunto de conceitos prévios são necessários; é necessário entender que os dados devem ser padronizados para um resultado válido e também para evitar erros de programação. Nesse tutorial de anotações pessoais descreverei o processo para criar um conjunto de dados para treinamento de uma rede neural.
Ambiente de desenvolvimento
Se ainda não tem nada configurado em seu sistema, não desanime; aliás, se empolgue, o processo já está todo descrito no artigo Deep Learning com Keras - primeiro passo. No caso, estou usando CUDA.
Paciência é a chave
Se formos fazer classificação de imagens, será necessário coletar um monte de imagens para tal. E não é só fazer um download gigante, é necessário padronizar o tamanho dessas imagens para que tenham dimensões iguais. Além disso, as imagens tem que ser diferentes, então não adianta querer trapacear fazendo múltiplas cópias de uma imagem com nomes diferentes para criar um dataset, certo? Nós já estaremos contando com data augmentation para ampliar a base de imagens.
Como baixar imagens para montar um dataset
Uma das formas é pegar no google images, com um pequeno truque:
Utilizando o google-chrome
Digite na barra de URL o nome da imagem que deseja baixar. Após carregar, clique no link Imagens do google, já no corpo do browser.
Utilize o atalho Ctrl+Shift+C. Isso abrirá o console do desenvolvedor na aba Elements. Mais abaixo terá uma opção Console (não é o Console ao lado de Elements, é embaixo mesmo).


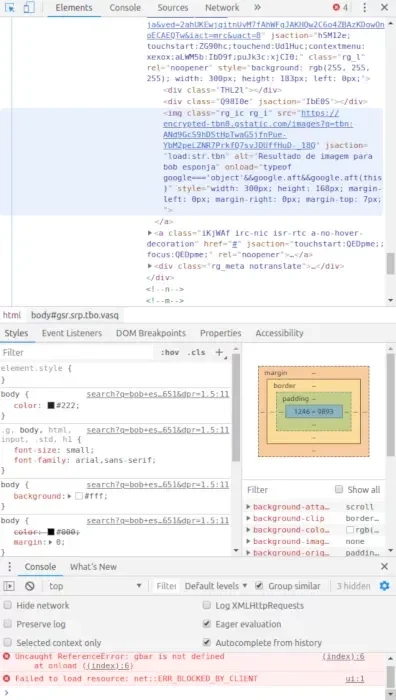
Role bastante a tela, o tanto quanto achar suficiente de imagens. Depois, cole esse código no console (cole de duas em duas linhas):
var script = document.createElement('script');
script.src = "https://ajax.googleapis.com/ajax/libs/jquery/2.2.0/jquery.min.js";
document.getElementsByTagName('head')[0].appendChild(script);
var urls = $('.rg_di .rg_meta').map(function() { return JSON.parse($(this).text()).ou; });
var textToSave = urls.toArray().join('\n');
var hiddenElement = document.createElement('a');
hiddenElement.href = 'data:attachment/text,' + encodeURI(textToSave);
hiddenElement.target = '_blank';
hiddenElement.download = 'urls.txt';
hiddenElement.click();
Com isso, um arquivo urls.txt será salvo pelo browser. Se quiser, mude a penúltima linha para o nome do respectivo personagem invés de deixar "urls.txt", assim fica mais fácil fazer essa operação toda de uma vez. Abra ao console, entre no diretório do respectivo personagem, copie o arquivo urls.txt para lá e então execute esse comando (sempre estou utilizando Linux, se estiver usando WIndows 10, procure por "bash" no menu e então proceda como descrito aqui):
cat urls.txt |while read line; do wget -c -T 5 --connect-timout=5 $line; done
Se ficar parado em alguma URL, interrompa com Ctrl+C, edite o arquivo e exclua a respectiva URL. Reinicie o processo (não se preocupe, arquivos já baixados serão pulados e não haverá desperdício de tempo). De qualquer modo, tem 2 timeouts diferentes pra tentar garantir que a conexão não fique presa em uma URL ruim e, se sua conexão for ruim, altere esses intervalos.
Descobrir arquivos que precisam ser renomeados
Por mais que possa lhe parecer estranho, não existe processo mais simples e rápido que utilizar o shell para manipular arquivos. Para saber os arquivos que precisam ser renomeados, execute esse comando no diretório da personagem:
ls|egrep -v 'jpg$|jpeg$|bmp$|png$|gif$'
Esse comando listará os arquivos, exceto os que já estão devidamente nomeados com as extensões jpg, png, jpeg, bmp e gif.
Depois que todos os arquivos estiverem com sua respectiva extensão...
Daí resta fazer a seleção manual das imagens. Pra não ficar uma zona, você pode renomear todos os arquivos de uma vez também, depois de devidamente renomeados (não se preocupe com o nome, o comando abaixo arrumará a bagunça toda):
i=0; ls *.{jpg,jpeg,png,gif}|while read line; do mv "$line" $i.$(echo "$line"|awk -F. '{print $NF}');i=$[i+1];done
Provavelmente alguns dos downloads não resultarão em imagens, devendo ser apagados.
Descobrindo a extensão do arquivo
Mas também, o arquivo pode ser baixado com um nome estranho. Por exemplo:


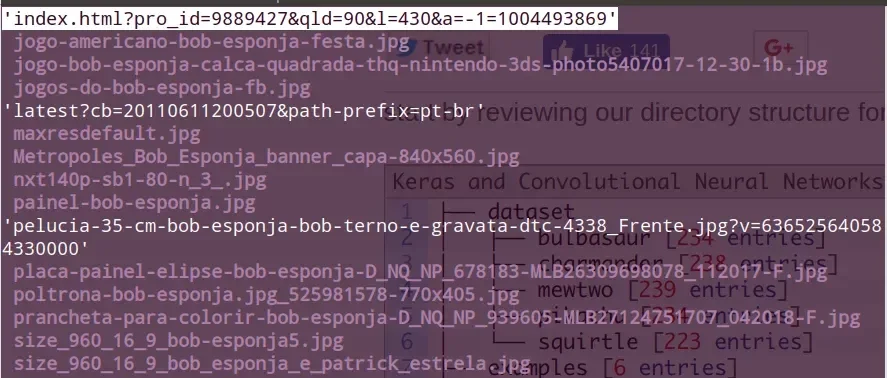
Nesse caso, pode-se verificar previamente o conteúdo, se desejar:
file 'index.html?pro_id=9889427&qld=90&l=430&a=-1=1004493869'
Se for uma imagem, retornará algo como:



Renomeando arquivos sem extensão
Nesse caso, basta renomear a imagem:
mv 'index.html?pro_id=9889427&qld=90&l=430&a=-1=1004493869' bob_seu_malandrinho.png
(Não fundamental) checar o arquivo nesse momento
E abrir para ver se a imagem está integra:
xdg-open bob_seu_malandrinho.png


Se não for uma imagem (após verificado com o comando file), simplesmente exclua-a:
rm -f index.html?media_id=141676752595822
Agilizando o processo para arquivos sem extensão com vestígios da extensão
Às vezes, a extensão está junto ao nome do arquivo. Por exemplo, "the-almighty-cthulhu-exists-in-the-rick-and-morty-universe.png?dpr=2&auto=format,compress&w=650". Pra ajudar reduzir um pouco mais o trabalho escravo, dá pra renomear esses arquivos por extensão:
EXT='jpg';a=0;ls|egrep -v 'jpg$|jpeg$|bmp$|png$|gif$'|grep $EXT|while read line; do \
mv "$line" $a-bcde.jpg;a=$[$a+1];done
Basta trocar o valor de $EXT de jpg para png e gif. Aí sobrará bem menos arquivos para analisar.
Arquivos com chamadas internas do shell
Pra finalizar, o último problema que pode ocorrer é a existência de arquivos com '--'. Isso dá um problema com o shell. Para resolver:
ls |grep '\-\-'|while read line; do mv "$line" $(echo "$line"|sed -re 's/-//g');done
Se tiver arquivo começado com '-', é pior ainda. Nesse caso:
rm -i -- "-*"
Diretório limpo: O antes e o depois
Usando essa combinação de comandos, além de ser rápido (um minuto limpa tudo que é possível), o residual não dá 5% de trabalho manual. Veja o antes e o depois:


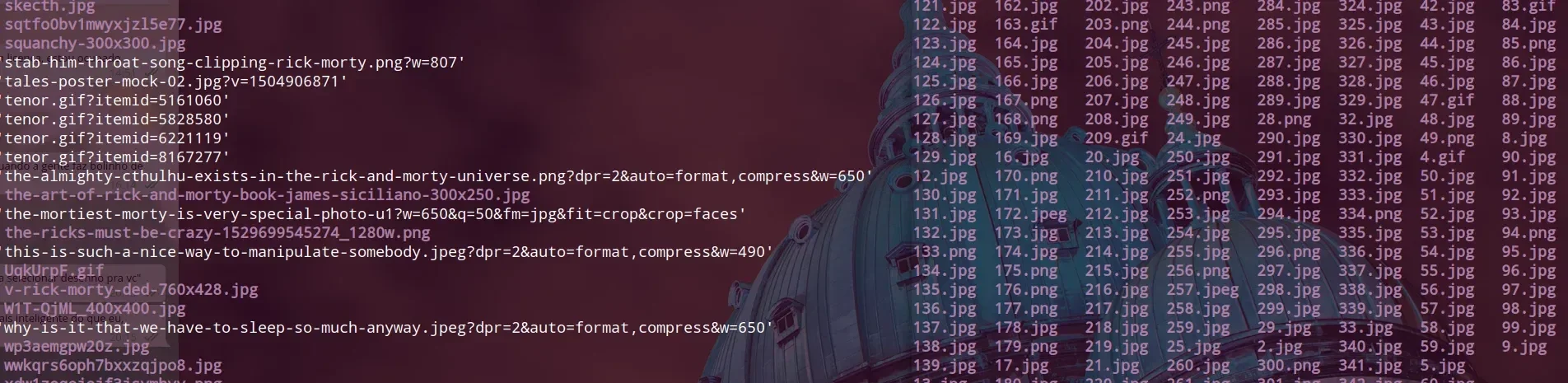
Parece muita coisa, mas assim as imagens ficam prontas em menos de 3 minutos. Agora é só repetir o processo nos demais diretórios.
Extrair frames usando ffmpeg
Essa é outra opção. O problema é que não devemos utilizar imagens iguais para criar um dataset, portanto será necessário fazer uma seleção mais apurada e, talvez seja uma boa ideia definir o número de quadros por segundo na extração (fps=X). Primeiro faça download de um vídeo qualquer que contenha o personagem. Para isso, vá ao youtube, pesquise o desenho, então selecione um vídeo. Não precisa assistir.
Clique com o botão direito sobre o vídeo e copie a URL. Depois, procure no google por "download video youtube". Selecione um dos sites e siga o processo para baixar o vídeo.
Depois, copie-o para o diretório do respectivo personagem e com o programa ffmpeg extraia os frames. Por exemplo:
ffmpeg -i input.mp4 -vf fps=5 out%d.png
Veja se a amostragem está boa, aumente ou diminua o número de frames, depois exclua o vídeo.
Selecionando as imagens
Para tal, basta navegar no diretório e fazer a seleção manual. É, um pouco de trabalho manual vai ter sim, e não é só a seleção. Ainda do console, simplesmente digite "xdg-open **. "**para abrir o gerenciador de arquivos diretamente no nível de diretório do personagem.
Criando o dataset
Primeiramente, crie o diretório do seu dataset com os subdiretórios referentes a cada classe. Suponhamos que queira criar um dataset para reconhecer alguns personagens de desenho. Criarei diretórios com os nomes deles para que cada um receba as respectivas imagens.
Minha lista:
- Bob esponja - Patrick e Bob
- Rick & Morty - Rick e Morty (ficou só rick porque quase todas as imagens tem ambos juntos ou só o rick)
- O incrível mundo de Gunball - Gunball e Darwin (Darwin só aparece o velho barbudo, então ficou só Gunball)
Como citado no tópico anterior, a amostragem boa seria um mínimo de 1.000 imagens por personagem, mas vou ficar com 1/4 disto, que já dará um total de 750 imagens.
O primeiro passo é criar os diretórios que receberão as imagens:
cd
mkdir -p dataset/{bob,patrick,rick,gunball}
As imagens devem ser colocadas em seus respectivos diretórios, conforme explicado anteriormente.
Estrutura de diretórios
Vamos considerar já os níveis de diretório e seu conteúdo. Seu dataset deve ser semelhante a essa estrutura (mas coloque apenas os diretórios que realmente receberão imagens).
mkdir -p vggNet/dataset/{examples,dobitaobyte}
O mesmo para os personagens, mas quando criei estava já dentro do nível de diretório do dataset.
cd vggNet/dataset
mkdir -p {bob,patrick,rick,morty,gunball,darwin}
dataset
Esse é o diretório master, onde disporemos os diretórios de personagens, cujo nomes de diretórios serão os labels.
examples
Diretório de imagens para testar nossa rede neural. Só para salientar, faremos uma CNN.
dobitaobyte
Esse diretório com nome lindão conterá a classe do modelo, implementado mais adiante. Será um módulo, mas deixarei a explicação disso para outro artigo.
Arquivos na raiz do dataset
Gráfico da acurácia e perda, gerado após o treinamento da rede neural, com o nome de results.png.
Objeto serializado, contendo os índices da nossa estrutura de treinamento, chamado lb.pickler. LabelBinarizer é a razão do prefixo.
O modelo que será treinado, chamado aqui de cartoons.model. Ele que nos permitirá a próxima brincadeira, em um artigo posterior.
O script de treinamento, chamado cartoon_train.py. Esse script fará todo o trabalho pesado.
O classificador, chamado cartoon_classify.py
Arquitetura da rede neural
Existem algumas arquiteturas já definidas em diversos estudos. Esse modelo é baseado no VGGNet de 2015, criado por Simonyan e Zisserman, cujo paper pode ser encontrado nesse link. Não estou habilitado a discorrer intensamente sobre a ciência por trás desse modelo, mas meu método de aprendizado consiste em saber que existe, fazer funcionar, entender como funciona, estudar o funcionamento e criar quando o conhecimento for suficiente. Não morra estudando, faça com que seja uma diversão antes de tudo e evolua conforme fizer o entendimento.
Características da arquitetura VGGNet
Usa apenas camadas convolucionais 3 × 3 empilhadas umas sobre as outras em profundidade crescente.
Redução do tamanho pelo max pooling.
Camadas "fully-connected" (completamente conectadas) ao final das camadas, antes do classificador softmax.
Implementação
Como sempre, diversos recursos serão utilizados. O model será o Sequential, utilizaremos novamente Conv2D, MaxPooling2D, a ativação, flatten, Dropout para desligar randomicamente neurônios para evitar overfitting etc.
Depois disponho os demais recursos que serão incluídos no programa, por enquanto vamos ver o que será utilizado nessa mini-VGGNet.
Dentro do diretório dobitaobyte crie o arquivo minivggnet.pye coloque o conteúdo:
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
class miniVGGNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
Carece explicação. Estamos construindo um módulo, por isso a definição de uma classe. O programa será composto por outros arquivos, mas vamos focar nesse e no que temos até agora.
O método build recebe as dimensões (que no caso serão arquivos de 96x96) e a profundidade será 3. O número de classes é o número de conjuntos que serão treinados. No caso, vamos treinar 4 cartoons, então passaremos 4 classes. Poderia ser mais ou menos, dependendo da sua paciência ou ansiedade.
O redimensionamento das imagens será feito automaticamente com a utilização de um recurso do OpenCV, implementado no código.
Estou utilizando apenas TensorFlow como backend por enquanto. Descrevi no artigo supracitado como instalar o TensorFlow para GPU, caso seja de seu interesse. Relacionado ao backend, o formato de entrada utiliza channels last para ordenação de dados, mas para usar o backend Theano isso seria channels first. Por isso a condicional ao final está checando o backend para saber a ordem do inputShape, cuja informação é encontrada na importação do backend, mais acima:
from keras import backend as K
Não se preocupe em escrever código agora, os disporei mais adiante de forma completa, atenha-se ao entendimento das explicações.
Primeiro bloco da rede convolucional
Já expliquei anteriormente a respeito, mas conforme vou aprendendo mais, consigo discorrer melhor a respeito, por isso vou colocando mais detalhes em artigos novos.
Basicamente, definimos a convolução, ativação e o polling (que não sei se a melhor tradução seria "eleição", ou "votação", ou outra coisa em redes neurais). Na convolução temos 32 camadas, kernel de 3x3, como quase todas as redes que implementei até agora nos artigos, sem o conhecimento científico necessário para definir por mim mesmo todos os valores. Mas não se decepcione por isso, pelo que vi, é muito comum utilizar modelagens convencionadas em papers.
Na camada de ativação utilizamos mais uma vez relu, como citado no artigo Deep Learning com Keras - primeira rede neural.
Na camada de polling, o parâmetro pool_size está definido como 3x3, que significa uma redução das dimensões de 96x96 para 32x32 ( pense na divisão: 96/3 = 32). Esse primeiro bloco fica desse jeito:
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
Pra reforçar a ideia do Dropout, desligando aleatoriamente os neurônios permitirá que haja redundância, de forma a garantir que uma determinada predição fique exclusivamente por conta de um nó específico.
Empilhar múltiplos CONV e RELU ajuda a reconhecer mais características do conjunto de dados, por isso a classificação de imagens aparece na modelagem sempre com mais camadas; mais comumente 2 ou 3 ocultas.
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
Tem uma sacada também em relação às reduções de uma camada para outra. É fácil encontrar no google images desenhos mostrando algumas reduções continuadas.
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
Pra finalizar, temos mais uma camada (FC) e o classificador softmax. O Full-Connected tem uma densidade de 1024 com ativação relu.
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
O Dropout nessa última camada está como nos artigos anteriores; 0.5 representa 50% dos nós desconectados durante o treinamento e, nas camadas anteriores, utiliza-se algo entre 0.1 e 0.25, como mostrado no artigo Como fazer predição de imagens com Keras e OpenCV, onde utilizei CIFAR-10, descrito no artigo Classificação de imagens usando Keras.
Código completo
Para não alongar demais o artigo, vou dispor os códigos completos e só algum comentário no que for necessário.
No diretório do módulo, temos o minivggnet.py:
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
class miniVGGNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# FC => RELU
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
E um arquivo vazio, __init__.py
#Estou vazio
Arquivos de código na raiz da estrutura
Um deles é o classify.py:
# USAGE
# python classify.py --model cartoon.model --labelbin lb.pickle --image examples/img_test.png
from keras.preprocessing.image import img_to_array
from keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
image = cv2.imread(args["image"])
output = image.copy()
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
print("[INFO] loading network...")
model = load_model(args["model"])
lb = pickle.loads(open(args["labelbin"], "rb").read())
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idx = np.argmax(proba)
label = lb.classes_[idx]
filename = args["image"][args["image"].rfind(os.path.sep) + 1:]
correct = "correct" if filename.rfind(label) != -1 else "incorrect"
label = "{}: {:.2f}% ({})".format(label, proba[idx] * 100, correct)
output = imutils.resize(output, width=400)
cv2.putText(output, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
print("[INFO] {}".format(label))
cv2.imshow("Output", output)
cv2.waitKey(0)
Se compararmos com as redes dispostas anteriormente, dá até um pouco de alegria, porque existe muita semelhança nessa composição, de forma que com a recorrência de construção de redes neurais, vai ficando mais simples compor o código!
O outro arquivo que fica na raiz é o train.py:
# USAGE
# python train.py --dataset dataset --model cartoon.model --labelbin lb.pickle
import matplotlib
matplotlib.use("Agg")
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.preprocessing.image import img_to_array
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from dobitaobyte.minivggnet import miniVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import numpy as np
import argparse
import random
import pickle
import cv2
import os
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", type=str, default="results.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
EPOCHS = 100
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
data = []
labels = []
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = img_to_array(image)
data.append(image)
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
print("[INFO] data matrix: {:.2f}MB".format(
data.nbytes / (1024 * 1000.0)))
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.2, random_state=42)
aug = ImageDataGenerator(rotation_range=25, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
print("[INFO] compiling model...")
model = miniVGGNet.build(width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
depth=IMAGE_DIMS[2], classes=len(lb.classes_))
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
print("[INFO] serializing network...")
model.save(args["model"])
print("[INFO] serializing label binarizer...")
f = open(args["labelbin"], "wb")
f.write(pickle.dumps(lb))
f.close()
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="upper left")
plt.savefig(args["plot"])
Aproveito para recomendar um excelente site de onde tiro muitas referências e códigos funcionais sobre OpenCV e atualmente, sobre redes neurais (que é o mais raro em exemplos de todos os tipos), cuja leitura é em inglês, mas o material é de outro mundo! Clique aqui para ir ao PySearchImage.
Resumo do processo
Pode parecer um monte de coisas por causa do detalhamento das informações, mas basicamente:
- Cria-se a estrutura de diretórios do dataset (personagens, módulo e exemplos).
- Cria-se os arquivos do módulo (__init__.py e minivggnet.py).
- Cria-se os arquivos Python na raiz do dataset (classify.py e train.py).
- Faz-se download das imagens para o treinamento .
- Organiza-se os arquivos baixados (essa é a parte mais trabalhosa).
Basicamente, é isso. Quando o treinamento for executado, serão criados na raiz do dataset os arquivos results.png (ou plot.png, contendo loss e acurracy), lb.pickle (labels binarizados do dataset), cartoon.model (pesos do treinamento).
Fazer a seleção das imagens é a parte mais decepcionante, vem um monte de imagem ruim no meio e acabei ficando com diretórios contendo pouco mais de 100 imagens. Vamos ver como fica a acurácia ou se terei que baixar mais, ou mudar personagens.
Treinamento da rede neural
Como citei acima, utilizei poucas imagens e isso impacta bastante nos resultados, mas confesso que fiquei impressionado! Apesar de ter dado um nível altíssimo de perda no treinamento, não houve 1 falso-positivo na classificação!
Preciso melhorar o dataset, tanto em volume quanto em qualidade, mas não tive paciência de repetir o processo antes de ver se valeria a pena o esforço. Vale. Muito.
Veja os (terríveis) resultados do treinamento:


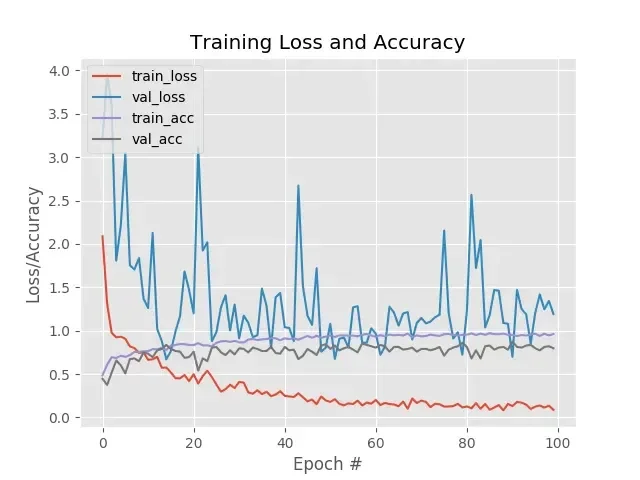
A imagem de destaque foi uma peça que fiz do Rick, antes do polimento (por isso está bem mal acabada). Logo sai um tutorial de modelagem, molde de silicone a peça em resina epoxi, só estou aperfeiçoando as técnicas.
https://www.instagram.com/p/BsDK82Jn6y9/
Inacreditável ou não (o reconhecimento)?
Vídeo
Vou fazer o vídeo com algumas classificações, desconsiderando a mensagem de "incorrect", só teve acerto! Logo mais estará no nosso canal DobitAoByteBrasil no Youtube, não deixe de se inscrever e clicar no sininho para receber notificações. Aproveite e, se curtiu esse artigo, deixe seu like alí na nossa página do facebook, no canto direito superior aqui do site!
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.