




Manual
do
Maker
.
com
Classificação de imagens usando Keras



O uso de IA para classificação de imagens talvez seja a aplicação mais divertida que poderíamos fazer com Keras. Nesse artigo veremos como utilizar o CIFAR-10, que é um dataset composto por 60k imagens coloridas de dimensão 32x32 pixels, sendo 50.000 para treinamento e 10.000 para teste.
Para utilizar esse dataset, construiremos uma CNN (Convolutional Neural Network) que reconhecerá as imagens com considerável precisão.
Gostaria de sugerir que não copie o código antes de chegar ao final do artigo, porque uma parte desse código inicial não está adequado e estou dispondo duas possibilidade próximo da conclusão.
Documentação do Keras
A documentação é originalmente em inglês, não há muito o que se fazer a não ser colocar no Google Translator para os que não sabem inglês. Se procurar por exemplos de uso de classificação, sempre haverá algum recurso (ou vários) sem explicação, porque pressupõe-se que tais conceitos já foram absorvidos. Nesse caso, é sempre uma boa ideia consultar a documentação para não deixar lacunas no aprendizado.
O site oficial do Keras é esse.
Classificação de imagens com Keras e CIFAR-10 dataset
Esse dataset serve para classificação de imagens. As informações a respeito já estão descritas acima, nessa sessão vou deixar esse link para donwload (não baixe ainda) e uma demonstração das classes contidas nesse dataset:



As classes são completa e mutualmente exclusivas, não havendo sobreposição entre carros de passeio e caminhões, por exemplo.
Existem 3 versões do dataset, uma em Python, uma em Matlab e uma versão binária para programadores C. O tutorial será em Python, portanto recomendo a primeira opção.
No Linux, já dentro do container Docker, baixe o dataset com o programa wget. Se não estiver instalado, preceda o download com o primeiro comando descrito abaixo:
apt-get install wget
wget -c https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
tar zxvf cifar-10-python.tar.gz
Será criado um diretório chamado cifar-10-batches-pycontendo lotes de dados nomeados como data_batch_1 até 5. Também haverá um test_batch para testes.
Leitura dos batches
Cada um desses arquivos do CIFAR-10 é um objeto produzido com cPickle. Meu ambiente está compilado para trabalhar com Python 2.7. A rotina para abrir um desses arquivos e retornar um dicionário é essa:
def unpickle(file):
import cPickle
with open(file, 'rb') as fo:
dict = cPickle.load(fo)
return dict
Se por acaso estiver utilizando um ambiente diferente do descrito nesse artigo e sua versão do Python for a 3, a rotina seria essa:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
Formato dos dados
Abrindo-o desse modo, cada dicionário conterá os seguintes elementos:
- data - um array numpy de 10000x3072 do tipo uint8. Cada linha de arrays armazena uma imagem colorida de 32x32. As primeiras 1024 entradas contém os valores do canal Red, depois, de forma repetida para os canais Green e Blue.
- labels - uma lista de 10000 números na faixa de 0 a 9. Os números no índice i indicam o rótulo da imagem no array data.Outro arquivo contido no dataset é o batches.meta. Ele também contém um dicionário Python. Suas entradas:
- label_names - uma lista de 10 elementos que dão nomes significativos aos labels numéricos no array labels supracitado. Por exemplo, label_names[0] == "airplane" e daí por diante.
Construindo a rede neural
Haverá um pouco mais de recurso utilizado nesse tutorial, já que classificar imagens é algo um pouco mais elaborado. Só de imports já dá uma sensação de que problemas estão por vir, mas não se preocupe, basta seguir o procedimento com tranquilidade. Minha recomendação é que primeiro faça a leitura do artigo até o final, sem compromisso de implementação, apenas para fazer o entendimento. Depois, retome e inicie o processo de implementação, já sabendo o que esperar. Isso te deixará menos ansioso e as coisas serão mais claras.
Headers ou imports
Quando estamos desenvolvendo, claro que não descemos da primeira à última linha de código com tudo em mente. Diversos momentos diferentes temos que incluir alguma biblioteca, mudar uma função, depois tem debug, etc. Em tutorial é tudo lindo, é Ctrl+C e Ctrl+V. Por mais essa razão não é necessário se preocupar, use o tempo poupado para fazer o entendimento, porque se for apenas copiar, colar e executar, o aprendizado irá por água abaixo. É assim que faço. Inclusive, se no meio de uma leitura eu vejo uma citação de algo que presumo que deveria saber previamente, paro a leitura e procuro referências sobre o tema. Não tenha preguiça de fazê-lo.
Uma coisa importante a notar nos imports é que poderíamos simplesmente importar o Keras:
import keras
Mas tudo o mais que não será usado viria junto para a memória. importando como está agora abaixo, apenas o que será utilizado estará residente na memória. Por isso, nem são tantos imports, se você reparar.
# Import all modules
import time
import matplotlib.pyplot as plt
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Activation
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from keras_sequential_ascii import sequential_model_to_ascii_printout
from keras import backend as K
if K.backend()=='tensorflow':
K.set_image_dim_ordering("th")
# Import Tensorflow with multiprocessing
import tensorflow as tf
import multiprocessing as mp
# Loading the CIFAR-10 datasets
from keras.datasets import cifar10
Reparou a última linha? O Keras tem alguns manipuladores de datasets. No tutorial do MNIST ficou claro o download automático do dataset; o processo será o mesmo.
Podemos aproveitar para declarar o tamanho do batch e o número de classes a utilizar.
batch_size = 32
num_classes = 10
epochs = 100
Quanto menor o batch, mais updates em um epoch. O epoch é o número de repasses, já explicado em outro artigo. Se não estiver utilizando GPU, não desanime, largue o computador e vá curtir uns dias de férias com a família.
Carregamento do dataset
Agora é a primeira parte bacana, com o conforto de deixar o "trabalho duro" por conta da API. Para carregarmos o modelo, simplesmente fazendo duas tuplas que conterão os dados inicias:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Depois de carregado, devemos fazer casting dos dados porque eles são carregados como inteiros e necessariamente devem ser notação de ponto flutuante.
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Modelagem da CNN
Dá pra fazer de várias maneiras, vou discorrer a respeito conforme estiver mais habituado com sua composição. O número de camadas pode variar, pode ser bom ou pode ser ruim, dependendo de um monte de fatores. Espero em breve mostrar um exemplo da mesma forma que aprendi que "mais" não significa "melhor".
Com 4 camadas o modelo fica desse jeito:
def base_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
sgd = SGD(lr = 0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
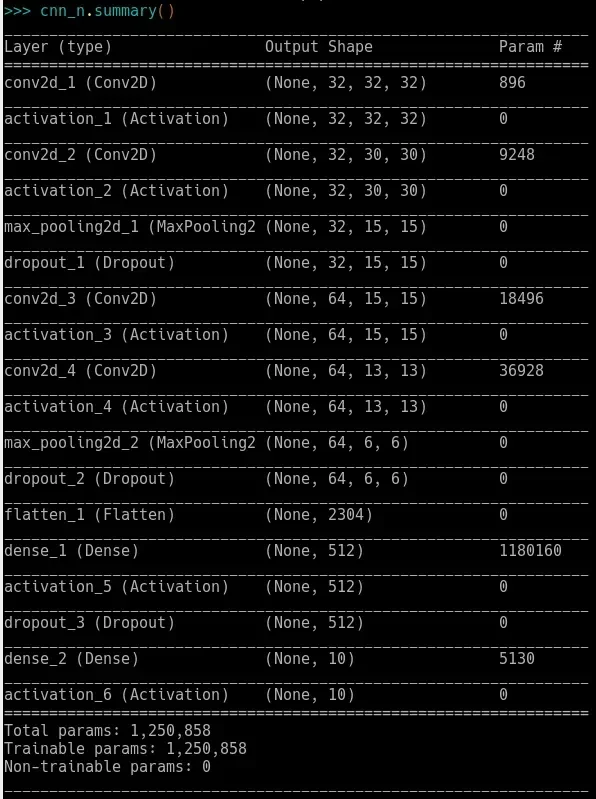
cnn_n = base_model()
cnn_n.summary()
cnn = cnn_n.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test,y_test),shuffle=True)
Não é uma má ideia fazer uma função para comportar a estrutura da modelagem da rede, podendo inclusive permitir experimentação, criando outras funções com variação de camadas. Quanto mais camadas, maior o tempo de treinamento e, acredite, esse treinamento não será dos mais leves.
A impressão do sumário deve retornar algo como:


O treinamento começou 00:35 com 3% de acurácia.
01:35 estava em 10% de acurácia. Restavam algumas horas ainda de treinamento, mas se não houvesse uma curva significativa no aprendizado, a decepção seria grande.
02:35 e a maioria das interações mostravam 0.0991. A angustia começou a tomar conta.
03:00 chega. Estava compilando na CPU. Pense num cara burro. Sofri por horas tentando compilar o TensorFlow a partir do momento que consegui jogar pra GPU e percebi que a versão do TensorFlow foi compilada com uma cudnn diferente da que eu tinha no computador.
09:30 fui dormir. Quando acordei, retomei, tentei fazer com uma imagem docker do TensorFlow, mas nada dava certo. Pesquisando no google, achei um repositório das versões do cudnn. Pior que não posso recomendar porque tudo vai depender da versão do seu TensorFlow e da versão CUDA e cudnn. Vai ter que ser na sorte.
18:55 enfim, compilando. Mas a acurácia não passava de 10%. O que estava errado? Como citei no início da série, não sou especialista em redes neurais e só utilizei frameworks profissionalmente para implementar junto com recursos de visão computacional. Mas mexendo aqui e ali, trocando camadas e chorando muito, acabei trocando o otimizador. Cara, o otimizador. Redes neurais não são feitas para amadores.
Optimizers
Na documentação do Keras tem o mesmo exemplo que usei com o otimizador SGD. Demorei demais pra suspeitar, mas por falta de conceitos.
SGD
O SGD é o Stochastic Gradient Descent. Vou ter que fazer um artigo bem chato falando sobre otimizadores.
Na documentação estão citados todos os suportados, mas não está claro o que fazem. Vou fazer experimentações. Por exemplo, o Adadelta "é uma versão mais robusta do Adagrad que adapta as taxas de aprendizado baseado no movimento das janelas de updates do gradiente. Desse modo, ele contia aprendendo quando muitos updates foram feitos. Comparado ao Adagrad em sua versão original do Adadelta, você não tem que configurar uma taxa inicial de aprendizado. Nessa versão a taxa inicial de aprendizado e fator decay podem ser configurados, assim como na maioria dos otimizadores do Keras".
Parece bacana, mas funciona como? Quando deve ser utilizado? Por isso farei um artigo somente sobre otimizadores.
Adam
Troquei por esse otimizador e logo no começo do treinamento, chegou a 39%. Será que o ideial seria modificar parâmetros do SGD ou tudo bem trocar só para aumentar a pseudo-acurácia?
Acurácia e perda
Já mostrado em outros artigos, imprimir os scores nos permite avaliar o resultado do trabalho. Para tal, incluímos duas linhas mais.
scores = cnn_n.evaluate(x_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
Aí terminou o treinamento e:



Além de não ficar muito alta a precisão, ainda teve um loss altíssimo. O que fiz? Consultei um especialista, claro. Daí o Leonardo Lontra disse para criar um modelo mais profundo. Bem, até aqui já tive que mudar coisas no sistema operacional e no programa, além de passar uma quantidade enorme de horas testando e treinando o model. Há de se ter persistência então, vamos lá; enquanto não recebo as dicas, vou dando uns pulos.
Mexi em algumas coisas pra ver em que resultava; mudei o parâmetro loss de multi-classe para regressão, mudei a densidade da saída para 32 e algumas coisinhas mais. Para não testar com 100 epochs, baixei para 2 e assim pude ter uma ideia ao final se o ajuste resultara em algo positivo.



É, ainda não está muito bom, mas melhorou de uma maneira fantástica.
Com um pedacinho do treino já deu 0.27 de precisão e 0.08 de perda. No treinamento anterior deu 0.47 de precisão e 0.37 de perda. Inegavelmente melhor. Daí, decidi rodar o aprendizado completo para ver o quanto baixaria, pois vi uma diferença de 0.0859 para 0.0816 em poucas linhas.
Com 20 epochs o valor de loss já estava em 0.0411 e a acurácia estava em 0.7127. Fantástico! Com o treinamento finalizado, a precisão ficou em 74.7%. Tá ruim mas tá bom. Em loss ficou com 0.0363; menos que 4%. Eu já me daria por satisfeito, mas lembra que citei o Leonardo Lontra mais acima? Pois então, enquanto eu fazia esse deep learning, ele preparou um modelo baseado no Squeezenet, com leves modificações. A que eu fiz oi baseado em 2 modelos, cada um tinha suas características e fui testando, mas no final tive que mexer também. Vejamos como ficou esse modelo que treinei:
# Import all modules
import time
import matplotlib.pyplot as plt
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.layers import Activation
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from keras_sequential_ascii import sequential_model_to_ascii_printout
import tensorflow as tf
import multiprocessing as mp
from keras.datasets import cifar10
batch_size = 32
num_classes = 10
epochz = 100
global density
density = 10 #512
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0
#ok
def base_model():
global density
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(32))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(density))
model.add(Activation('softmax'))
#model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#para classificacao binaria
#binary_crossentropy
#para regressao
#mse
#para multiclasse
#categorical_crossentropy
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
return model
cnn_n = base_model()
cnn_n.summary()
cnn = cnn_n.fit(x_train, y_train, batch_size=batch_size, epochs=epochz, validation_data=(x_test,y_test),shuffle=True)
scores = cnn_n.evaluate(x_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
Agora vamos testar o modelo fornecido pelo Lontra. Rodei com 20 epochs, já na primeira foi um susto; loss com 1.7603, mas acurácia começou alta também. Foi 0.4050 de cara!
O tempo por epoch foi quase o triplo, mas em 7 epochs já estava em 67% de precisão com loss de 0.8509. Fiquei só na expectativa. O modelo que fiz acima tem uma curva que para de crescer em dado momento, então 100 epochs não são necessários. Com a metade já fica bem próximo do resultado final.
O resultado do código do Lontra com 20 epochs:



Não ficou muito atrativo com poucos epochs, mas o treinamento ainda estava crescendo. Nesse caso, vale a pena continuar. Já dei uma modificada no dropout, por sugestão dele. O dropout desativa neurônios aleatoriamente para prevenir overfiting. Baixei o número de epochs para 6, só para comparar o resultado; mas não melhorou, então vou compilar com 100 epochs pra comparar de igual pra igual. Mas por enquanto, já disponibilizo o código, que tem informações preciosas, mostrando como fazer a predição, salvamento automático do treinamento etc!
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from keras.models import Model
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, GlobalMaxPooling2D
from keras.layers import concatenate, BatchNormalization, Activation, Dropout
from keras import backend as K
import numpy as np
def img_to_array(img, image_data_format='default'):
"""Converts numpy image into channels_first/channels_last format
:param img: Numpy array x has format (height, width, channel) or (channel, height, width)
"""
if image_data_format == "default":
image_data_format = K.image_data_format()
if image_data_format not in ['channels_first', 'channels_last']:
raise Exception('Unknown image_data_format: ', image_data_format)
x = np.asarray(img, dtype=K.floatx())
# colored image
# (channel, height, width)
if len(x.shape) == 3:
if image_data_format == 'channels_first':
x = x.transpose(2, 0, 1)
# grayscale
elif len(x.shape) == 2:
# already for th format
x = np.expand_dims(x, axis=0)
if image_data_format == 'channels_last':
# (height, width, channel)
x = x.reshape((x.shape[1], x.shape[2], x.shape[0]))
# unknown
else:
raise Exception('Unsupported image shape: ', x.shape)
return x
def fire_module(x, fire_id, squeeze=16, expand=64, fire_blockname=''):
f_name = "fire{0}/{1}"
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
x = Conv2D(squeeze, (1, 1), padding='same', name=f_name.format(fire_id, "squeeze1x1"))(x)
x = BatchNormalization(axis=channel_axis)(x)
left = Conv2D(expand, (1, 1), padding='same', name=f_name.format(fire_id, "expand1x1"))(x)
right = Conv2D(expand, (3, 3), padding='same', name=f_name.format(fire_id, "expand3x3"))(x)
return concatenate([left, right], axis=channel_axis, name=f_name.format(fire_id, "concat") + fire_blockname)
def SqueezeNet(inputs, num_classes=None, include_top=True, dropout=0.5, fireplus=False, pooling=None):
"""Keras implementation of SqueezeNet v1.1 implementation
:param inputs: input layer.
:param num_classes: The number of outputs at final softmax layer
:param include_top: if true, includes classification layers.
:param dropout: dropout rate.
:param fire_kwargs: dict with key-value for all convolutions in fire module.
For change parameters in conv2d layer. Default is {"activation" : 'relu'}
:param conv_kwargs: dict with key-value for first convolution layer.
For change parameters in conv2d layer. Default is {"activation" : 'relu'}
:param fireplus: added two extra fire module
:param pooling: Optional pooling mode for feature extraction
when `include_top` is `False`.
- `None` means that the output of the model
will be the 4D tensor output of the
last convolutional layer.
- `avg` means that global average pooling
will be applied to the output of the
last convolutional layer, and thus
the output of the model will be a
2D tensor.
- `max` means that global max pooling will
be applied.
:returns: SqueezeNet model
"""
if pooling not in ['max', 'avg', None]:
raise ValueError("Invalid value for pooling.")
x = Conv2D(64, (3, 3), strides=(2, 2), padding='same', name='conv1')(inputs)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same', name='pool1')(x)
x = fire_module(x, fire_id=2, squeeze=16, expand=64)
x = fire_module(x, fire_id=3, squeeze=16, expand=64, fire_blockname='/block1')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same', name='pool_block1')(x)
x = fire_module(x, fire_id=4, squeeze=32, expand=128)
x = fire_module(x, fire_id=5, squeeze=32, expand=128, fire_blockname='/block2')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same', name='pool_block2')(x)
x = fire_module(x, fire_id=6, squeeze=48, expand=192)
x = fire_module(x, fire_id=7, squeeze=48, expand=192, fire_blockname='/block3')
x = fire_module(x, fire_id=8, squeeze=64, expand=256)
x = fire_module(x, fire_id=9, squeeze=64, expand=256, fire_blockname='/block4')
# extra fire modules
if fireplus:
x = fire_module(x, fire_id=10, squeeze=96, expand=384)
x = fire_module(x, fire_id=11, squeeze=96, expand=384, fire_blockname='/block5')
if not include_top:
if pooling == 'avg':
x = GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = GlobalMaxPooling2D()(x)
else:
if dropout != 0.0:
x = Dropout(dropout)(x)
x = Conv2D(num_classes, (1, 1), strides=(1, 1), padding='valid')(x)
x = GlobalAveragePooling2D()(x)
x = Activation('softmax')(x)
return Model(inputs=inputs, outputs=x)
if __name__ == '__main__':
import keras.datasets as dataset
from keras.utils import to_categorical
from keras.layers import Input
import os
image_data_format = 'default'
datasetname = "cifar10"
mode = 'train'
epochs = 20
model_fn = 'squeezenet_{0}.h5'.format(datasetname)
if datasetname == "mnist":
rows, cols = 28, 28
channels = 1
nb_classes = 10
batch_size = 32
elif datasetname == "cifar10":
rows, cols = 32, 32
channels = 3
nb_classes = 10
batch_size = 10
if image_data_format == "default":
image_data_format = K.image_data_format()
if image_data_format == 'channels_first':
input_shape = (channels, rows, cols)
elif image_data_format == 'channels_last':
input_shape = (rows, cols, channels)
else:
raise NotImplementedError("channels_first or channels_last are only available")
inputs = Input(shape=input_shape)
model = SqueezeNet(inputs, num_classes=nb_classes, fireplus=True)
if mode == 'train':
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])
print(model.summary())
# restore weights
if os.path.exists(model_fn):
model.load_weights(model_fn)
# the data, shuffled and split between train and test sets
datasetname = getattr(dataset, datasetname)
(X_train, y_train), (X_test, y_test) = datasetname.load_data()
if K.image_data_format() == 'channels_first':
X_train = X_train.reshape(X_train.shape[0], channels, cols, rows)
X_test = X_test.reshape(X_test.shape[0], channels, cols, rows)
else:
X_train = X_train.reshape(X_train.shape[0], cols, rows, channels)
X_test = X_test.reshape(X_test.shape[0], cols, rows, channels)
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
X_train /= 255
X_test /= 255
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = to_categorical(y_train, nb_classes)
Y_test = to_categorical(y_test, nb_classes)
model.fit(X_train,
Y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, Y_test))
validationAccuracy = model.evaluate(X_test, Y_test, verbose=0)
print('\nValidation accuracy is : %f \n' % (100.0 * validationAccuracy[1]))
model.save_weights(model_fn, overwrite=True)
elif mode == 'predict':
import cv2
import time
import sys
model.load_weights(model_fn)
img = cv2.imread(sys.argv[1], 0)
img = cv2.resize(img, (rows, cols))
x = img_to_array(np.float32(img) / 255.0)
x = np.expand_dims(x, axis=0)
start_t = time.time()
res = model.predict(x, verbose=0)
print("took ", time.time() - start_t)
print("class index: ", res.argmax())
Farei um vídeo mostrando minhas experiências com a predição e os resultados do treinamento com esse dataset CIFAR10.
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.