




Manual
do
Maker
.
com
Recurrent Neural Network com Keras



Recurrent Neural Network e FeedForward
A RNN ou, "Recurrent Neural Network", é um tipo de rede neural desenhada para reconhecer padrões em sequência de dados como texto, genomas, reconhecimento de palavras por voz, time series para sensores, estoques de mercado etc. Esses algorítimos tem dimensão temporal. Mas RNNs também podem ser aplicadas em sequência de imagens e por essa razão, pode ser utilizada para "anomaly detection" ou, detecção de anomalia.
Dúvidas sobre time series? Leia:
Gerar gráficos com Grafana, Graphite, Carbon e Collectd
Grafana com InfluxDB e Telegraf para gerar gráficos
Uma rede neural recorrente á uma classe de rede em que as conexões entre nós forma um grafo direcionado ao longo de uma sequência, o que permite a exibição de comportamentos dinâmicos temporais para uma sequência de tempo.
O problema com Vanilla Recurrent Neural Network construída de nós de rede regulares é que como tentamos odelar dependências entre palavras ou sequências de valores que são separados por um número significativo de palavras, nos deparamos com o problema de Vanish Gradient (explicado mais adiante). Para resolver esse tipo de problema, utiliza-se redes LSTM.
FeedForward
Em uma rede FeedForward uma série de operações matemáticas passam pelos nós (como em qualquer outra NN) e ela é alimentada sem que um nó seja tocado duas vezes seguidas, enquanto os outros ciclos através do loop e próximos são chamados "recorrentes".
Uma FeedForward é treinada em imagens rotuladas até que minimize o erro advindo de suas categorias. Com o conjunto de parâmetros treinados (ou pesos, ou model), evoluindo para categorização de dados que nunca foram vistos. Uau!
Uma rede feedforward treinada pode ser exposta a qualquer coleção aleatória de imagens e a primeira imagem (ou fotografia) a que está sendo exposta não necessariamente alterará como será classificada a segundo. Isso significa que a foto de um gato não induzirá a rede a ver um elefante.
Em relação ainda à rede feedforward, ela não tem noção de ordem no tempo, considerando apenas o exemplar a qual foi exposta. Seu passado recente é esquecido (não confunda com DNN, que é Deep Neural Network, não Dory Neural Network). Isso significa que ela precisa ser fortemente influenciada para mudar uma percepção.
Recurrent Neural Network
Por outro lado, as Recurrent Neural Network usam mais do que o exemplo de entrada visto, mas também o que foi visto anteriormente. A decisão dessa rede está relacionada ao tempo e ela é afetada pela decisão de t-1. Isso significa que essa rede tem duas fonts de entrada, a presente e o passado recente, que combinam-se para determinar como responder a um novo dado, muito mais parecido com o que fazemos na vida real. Uau de novo!
Recurrent vs Feedforward
As redes recorrentes são diferenciadas das redes feedforward pelo loop de feedback conectado às suas decisões anteriores, ingerindo suas próprias saídas momento após momento como entrada.
Uma rede recorrente é também tida como uma "rede com memória". E isso tem uma finalidade; há informações na própria sequência e as redes recorrentes a utilizam para executar tarefas que as redes feedforward não conseguem executar.
Long Short Term Memory (LSTM)
Para analise de dados estáticos utilizamos redes neurais do tipo CNN e DNN, classificando imagens com tranquilidade. Mas para dados dinâmicos como vídeo, reconhecimento de voz e sequência de textos é mais adequado fazer classificação utilizando redes neurais recorrentes. LSTM é um subconjunto das redes supracitadas.
Problemas comumente encontrados em redes neurais
É um assunto à parte, mas vale fazer uma citação de alguns dos problemas que encontramos e, em outro artigo, tratar dos modos de depuração de redes neurais.
Overfitting
Overfitting é o maior problema para análise preditiva, em especial, para redes neurais. Como já citado em outro artigo, trata-se do vício no treinamento da rede neural, onde ela acaba predizendo bem dados de seu dataset, mas classifica mal dados externos. Ela se torna mais significativa em deep learning, onde as redes neurais tem um largo número de camadas contendo muitos neurônios. O número de conexões desses modelos podem ser astronômicos, na casa dos milhões. Esse assunto será tratado em um artigo exclusivo.
Vanish gradient
Esse problema é particularmente problemático com funções de ativação sigmoid, mais difíceis de se encontrar em ANNs (Artificial Neural network) com gradientes baseados em métodos de aprendizado e back propagation. Nesses método, os pesos recebem update proporcional à derivativa parcial da função de erro em relação ao respectivo peso de cada interação do treinamento. Cada um dos termos merece artigos dedicados e os farei futuramente.
ReLU activation
A função ReLU é definida como:


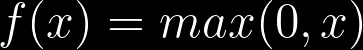
ReLU retorna 0 para valores negativos e x para valores maiores que 0. Quando valores negativos são necessários para o dar o peso isso se torna um problema, porque eles são simplesmente eliminados e isso impacta no aprendizado.
Quando os valores dos pesos são muito espessos tanto para negativo como para positivo
Como foi possível ver nos artigos anteriores, é bastante divertido brincar com redes neurais. Mas redes neurais não são apenas uma porção de código, nem existe um padrão absoluto a seguir, por isso de vez em quando farei algumas anotações sobre estudos.
Tanh
Tanh é a função de ativação tangente hiperbólica, que também é como uma sigmoid logística, mas conforme o artigo de referência, melhor. A faixa de tanh, diferente da função de ativação ReLU vai de -1 a 1. Sua vantagem é que as entradas negativas serão mapeadas fortemente e as entradas 0 serão mapeadas para próximo de 0. Trata-se de uma função diferencial, monotônica e principalmente utilizada em classificação entre duas classes. É a função de ativação utilizada em nossa RNN.
Perceptron
O perceptron é um algorítimo para aprendizado supervisionado de classificadores binários. Um classificador é uma função que calcula uma saída com base nos dados de entrada. As saídas são baseadas também nos pesos desses valores de entrada. É um assunto bem complexo e elaborado e, por não ser um especialista, vou apenas citar os conceitos.
Um perceptron é um algorítimo que recebe uma entrada x e devolve uma saída f(x) (um único valor binário).
Conforme se vai aprofundando no assunto, se faz cada vez mais necessário conhecer o funcionamento e compreender as funções matemáticas e estatísticas envolvidas, ou seja, infelizmente não dá pra fazer sempre por intuição; será necessário saber com bastante confiança o que se deseja.


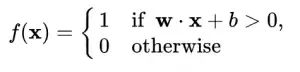
Se você leu o artigo PID - Proporcional Integral Derivativa, não se incomodará muito com as expressões que, em muitas das vezes, são simples.
Nessa expressão, w é um vetor de pesos, onde w * x é o dot product, expressado como:


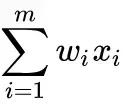
Nessa expressão, m é o número de entradas do perceptron. Se você já teve aulas de estatística, isso também não lhe causará espanto.
Dá para escrever diversos livros a respeito do assunto (para quem entende, claro). Só estou dispondo um mínimo de informação para saber que essas funções de rede neural não são algorítimos para controlar relés; realmente são elaborados e cada um deles tem uma aplicação específica. Além disso, existem funções semelhantes, como as funções de ativação relu, leakyrelu, prelue outras.
Vou tentar explicar alguma coisa em artigos de vez em quando. Esse pode ser considerado o primeiro que é só teoria e bem básico. Gradativamente vou criando novos artigos com mais e mais informação e, provavelmente voltaremos diversas vezes a um mesmo tema para fazer aprofundamento.
Recurrent Neural Network com Keras
Após abordar conceitos variados, podemos agora focar nessa rede neural sabendo qual é o seu propósito.
Uma rede LSTM é uma rede neural recorrente que tem blocos de células LSTM no lugar do padrão de redes neurais por camadas. Essas células tem vários componentes chamados de "portão de entrada". Uma representação gráfica tirada de um artigo de referência:


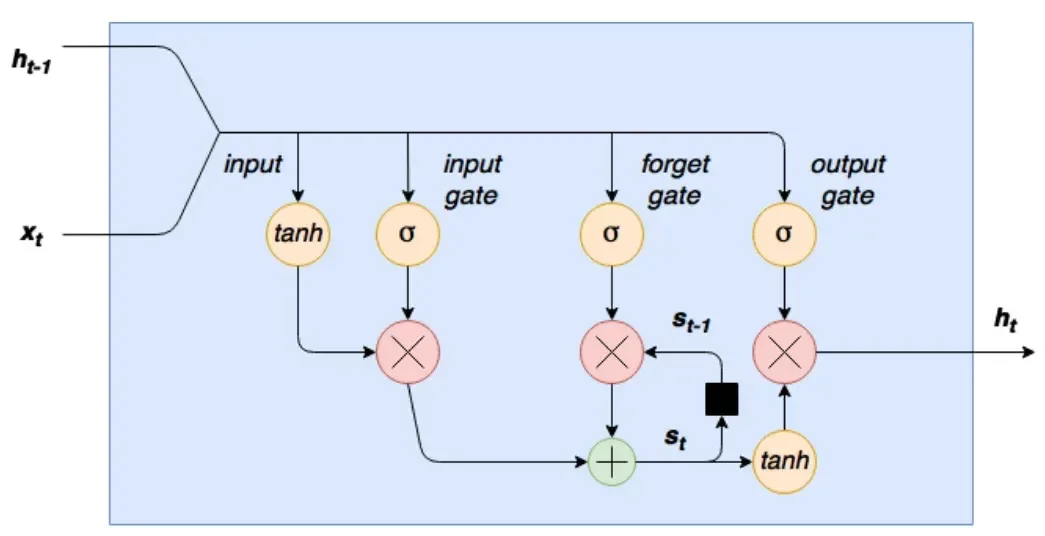
Do lado esquerdo temos nossas novas palavras (x_t), sendo concatenadas à saída prévia da célula do lado oposto:


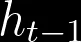
O primeiro passo para esta entrada combinada é que ela seja comprimida por meio de uma camada tanh. O segundo passo é que ela passe através de um portão de entrada (input gate). Um gate de entrada é uma camada de nós ativados por sigmoide cuja saída é multiplicada pela entrada comprimida. O resultado dessa sigmoid devolve valores entre 0 e 1 e essa proximidade pode definir o estado de saída. Espero que tenha alguma intimidade com IoT, porque a referência que faço é o estado de um pino, que tem o valor 1 para up e 0 para down. E é dessa forma que funciona.
O passo seguinte no fluxo de dados através destas células é o estado interno ou laço de esquecimento. As células LSTM tem um estado interno variável (s_t). Essa variável faz a recorrência efetiva através do passo:


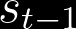
Essa operação de adição invés da operação de multiplicação ajuda a reduzir o risco de vanish gradients. Entretanto, esse loop de recorrência é controlado por um portão de esquecimento, que funciona como um portão de entrada, mas ajuda a rede a saber quais variáveis de estado devem ser lembradas ou esquecidas.
Finalmente, a camada de saída, que utiliza tanh invés de ReLU. Esse portão determina que valores são atualmente permitidos como uma saída para a célula h_t.
Código e dataset
Esse artigo é baseado no material disposto pelo AdventuresinML, cujo código pode ser pego no repositório git deles, nesse link. Também será necessário baixar o dataset, disponibilizado através desse outro link.
Construção do modelo LSTM em Keras
Vou citar superficialmente para manter o formato de anotação de conceitos. Para estudo, pegue o código e o dataset acima e desfrute; é o que farei por um bom tempo.
Propósito
Esse modelo tem o propósito de fazer predição de palavras para completar uma frase. O dataset é em inglês, por isso não é tão atrativo, mas é uma forma de exemplificar o modelo. Em seguida escreverei outro artigo com um exemplo bacana que encontrei.
Model
Poderia dispor aqui as partes do código e explicá-las, mas acredito ser desnecessário. Talvez a parte interessante seja justamente a modelagem, por isso vou me ater nisso, já que o código completo já está disponível para download.
model = Sequential()
model.add(Embedding(vocabulary, hidden_size, input_length=num_steps))
model.add(LSTM(hidden_size, return_sequences=True))
model.add(LSTM(hidden_size, return_sequences=True))
if use_dropout:
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(vocabulary)))
model.add(Activation('softmax'))
Como pode notar, o modelo é bem diferente das redes que dispus nos artigos anteriores. A segunda linha tem a camada de incorporação das palavras, convertendo-as em vetores. O primeiro argumento é o tamanho do dicionário. Por ser a primeira camada da rede, devemos especificar o tamanho do número de palavras por amostra (input_lenght).
A outra novidade é a camada LSTM, que recebe como primeiro parâmetro o número de nós para a camada oculta. O parâmetro return_sequences recebe um boolean para se certificar (ou não) que a célula retornara todas as saídas da célula LSTM através do tempo. Sem ele, a célula simplesmente retornará o valor do último passo.
Depois, segue o padrão. Compilar com o otimizador adam e categorical_crossentropy como função de perda. E tem uma métrica, só isso:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['categorical_accuracy'])
Callback para interação
Essa foi outra coisa que me despertou interesse. O Keras pemite a utilização de callbacks que podem ser chamadas no treinamento. Nesse exemplo foi utilizado o checkpoint. Ele salva o modelo após cada epoch, que permite o manuseio enquanto rodando um treinamento demorado.
checkpointer = ModelCheckpoint(filepath=data_path + '/model-{epoch:02d}.hdf5', verbose=1)
No caso, o modelo está sendo nomeado com o número do epoch atual. Isso é ótimo, porque ajuda testar diferentes compilações para determinar a quantidade ideal de epochs e depois descartar o restante. Daí resta só o fit:
model.fit_generator(train_data_generator.generate(), len(train_data)//(batch_size*num_steps), num_epochs,
validation_data=valid_data_generator.generate(),
validation_steps=len(valid_data)//(batch_size*num_steps), callbacks=[checkpointer])
Python argparse
Dei um tapinha de leve no código, mas foi por preguiça de ter que editar o código toda a vez que quisesse fazer uma interação com a evolução do treinamento. Além do mais, o caminho dos dados está hardcoded no formato windows, por isso modifiquei para parâmetro também.
A biblioteca argparse do Python nos permite definir parâmetros de uma maneira limpa, de modo que tudo o que for variável não precisará ser mexido no código diretamente toda a vez que for modificada a plataforma de execução ou diretórios padrão. Um código de exemplo:
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=False,
help="dataset path to build the model")
args = vars(ap.parse_args())
Com esse argumento por linha de comando, o diretório do dataset passa a ser um parâmetro variável não obrigatório. Isso significa que se for classificação, não será necessário passá-lo novamente. Porém, se for treinamento, ele não está sendo um parâmetro obrigatório e, por consequência, será obrigatório fazer uma condicional extra para validar a variável quando em caso de treinamento. Nessa situação é válido fazê-lo porque poderíamos estar carregando apenas o model para outro computador.
A linha args pega os argumentos em um dicionário, daí quando for utilizar a variável recebida por linha de comando, basta carregar o valor do dicionário:
directory = args["dataset"]
Já havia alguma coisa no código, mas não gosto de usar como estava. Modifiquei e adicionei uns parâmetros, como pode ser visto ao chamar o parâmetro '--help':


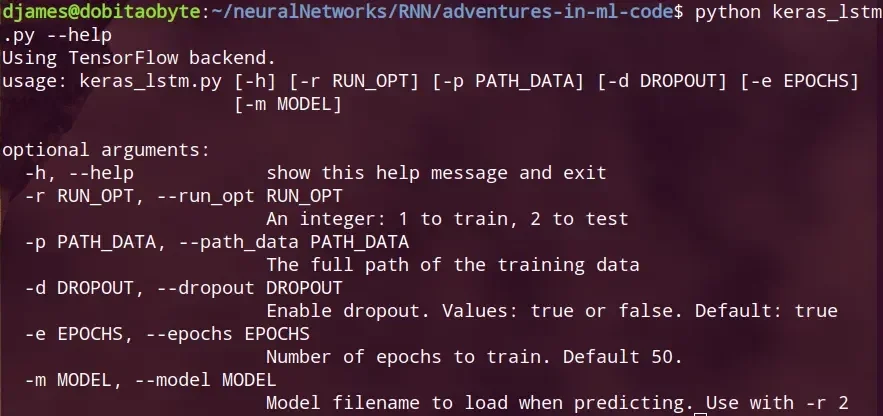
Para executar, essa seria uma das opções:
python keras_lstm.py -r 1 -p /home/djames/neuralNetworks/RNN/simple-examples/data
Como os parâmetros são opcionais, se não passar nenhum certamente haverá um erro no caminho para o dataset, mas podemos modificá-lo no código.
Código
E o código fica assim:
from __future__ import print_function
import collections
import os
import tensorflow as tf
from keras.models import Sequential, load_model
from keras.layers import Dense, Activation, Embedding, Dropout, TimeDistributed
from keras.layers import LSTM
from keras.optimizers import Adam
from keras.utils import to_categorical
from keras.callbacks import ModelCheckpoint
import numpy as np
import argparse
"""To run this code, you'll need to first download and extract the text dataset
from here: http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz. Change the
data_path variable below to your local exraction path"""
data_path = "C:\\Users\Andy\Documents\simple-examples\data"
parser = argparse.ArgumentParser()
parser.add_argument('-r', '--run_opt', type=int, default=1, help='An integer: 1 to train, 2 to test')
parser.add_argument('-p', '--path_data', type=str, default=data_path, help='The full path of the training data')
parser.add_argument('-d','--dropout',required=False, default=True, help='Enable dropout. Values: true or false. Default: true')
parser.add_argument('-e', '--epochs', required=False, default=50, help='Number of epochs to train. Default 50.')
parser.add_argument('-m', '--model', required=False, help='Model filename to load when predicting. Use with -r 2')
args = vars(parser.parse_args())
if 'path_data' in args:
data_path = args['path_data']
def read_words(filename):
with tf.gfile.GFile(filename, "r") as f:
return f.read().decode("utf-8").replace("\n", "<eos>").split()
def build_vocab(filename):
data = read_words(filename)
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: (-x[1], x[0]))
words, _ = list(zip(*count_pairs))
word_to_id = dict(zip(words, range(len(words))))
return word_to_id
def file_to_word_ids(filename, word_to_id):
data = read_words(filename)
return [word_to_id[word] for word in data if word in word_to_id]
def load_data():
# get the data paths
train_path = os.path.join(data_path, "ptb.train.txt")
valid_path = os.path.join(data_path, "ptb.valid.txt")
test_path = os.path.join(data_path, "ptb.test.txt")
# build the complete vocabulary, then convert text data to list of integers
word_to_id = build_vocab(train_path)
train_data = file_to_word_ids(train_path, word_to_id)
valid_data = file_to_word_ids(valid_path, word_to_id)
test_data = file_to_word_ids(test_path, word_to_id)
vocabulary = len(word_to_id)
reversed_dictionary = dict(zip(word_to_id.values(), word_to_id.keys()))
print(train_data[:5])
print(word_to_id)
print(vocabulary)
print(" ".join([reversed_dictionary[x] for x in train_data[:10]]))
return train_data, valid_data, test_data, vocabulary, reversed_dictionary
train_data, valid_data, test_data, vocabulary, reversed_dictionary = load_data()
class KerasBatchGenerator(object):
def __init__(self, data, num_steps, batch_size, vocabulary, skip_step=5):
self.data = data
self.num_steps = num_steps
self.batch_size = batch_size
self.vocabulary = vocabulary
# this will track the progress of the batches sequentially through the
# data set - once the data reaches the end of the data set it will reset
# back to zero
self.current_idx = 0
# skip_step is the number of words which will be skipped before the next
# batch is skimmed from the data set
self.skip_step = skip_step
def generate(self):
x = np.zeros((self.batch_size, self.num_steps))
y = np.zeros((self.batch_size, self.num_steps, self.vocabulary))
while True:
for i in range(self.batch_size):
if self.current_idx + self.num_steps >= len(self.data):
# reset the index back to the start of the data set
self.current_idx = 0
x[i, :] = self.data[self.current_idx:self.current_idx + self.num_steps]
temp_y = self.data[self.current_idx + 1:self.current_idx + self.num_steps + 1]
# convert all of temp_y into a one hot representation
y[i, :, :] = to_categorical(temp_y, num_classes=self.vocabulary)
self.current_idx += self.skip_step
yield x, y
num_steps = 30
batch_size = 20
train_data_generator = KerasBatchGenerator(train_data, num_steps, batch_size, vocabulary,
skip_step=num_steps)
valid_data_generator = KerasBatchGenerator(valid_data, num_steps, batch_size, vocabulary,
skip_step=num_steps)
hidden_size = 500
use_dropout=True
if 'dropout' in args:
if args['dropout'] == 'false':
use_dropout= False
model = Sequential()
model.add(Embedding(vocabulary, hidden_size, input_length=num_steps))
model.add(LSTM(hidden_size, return_sequences=True))
model.add(LSTM(hidden_size, return_sequences=True))
if use_dropout:
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(vocabulary)))
model.add(Activation('softmax'))
optimizer = Adam()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['categorical_accuracy'])
print(model.summary())
checkpointer = ModelCheckpoint(filepath=data_path + '/model-{epoch:02d}.hdf5', verbose=1)
num_epochs = args['epochs']
if args['run_opt'] == 1:
model.fit_generator(train_data_generator.generate(), len(train_data)//(batch_size*num_steps), num_epochs,
validation_data=valid_data_generator.generate(),
validation_steps=len(valid_data)//(batch_size*num_steps), callbacks=[checkpointer])
# model.fit_generator(train_data_generator.generate(), 2000, num_epochs,
# validation_data=valid_data_generator.generate(),
# validation_steps=10)
model.save(os.path.join(data_path, "final_model.hdf5"))
elif args['run_opt'] == 2:
model_to_load = "model-05.hdf5"
if 'model' in args:
if os.path.exists(os.path.join(args['path_data'],model_to_load)):
model_to_load = args['model']
model = load_model(os.path.join(data_path, model_to_load))
dummy_iters = 40
example_training_generator = KerasBatchGenerator(train_data, num_steps, 1, vocabulary,
skip_step=1)
print("Training data:")
for i in range(dummy_iters):
dummy = next(example_training_generator.generate())
num_predict = 10
true_print_out = "Actual words: "
pred_print_out = "Predicted words: "
for i in range(num_predict):
data = next(example_training_generator.generate())
prediction = model.predict(data[0])
predict_word = np.argmax(prediction[:, num_steps-1, :])
true_print_out += reversed_dictionary[train_data[num_steps + dummy_iters + i]] + " "
pred_print_out += reversed_dictionary[predict_word] + " "
print(true_print_out)
print(pred_print_out)
# test data set
dummy_iters = 40
example_test_generator = KerasBatchGenerator(test_data, num_steps, 1, vocabulary,
skip_step=1)
print("Test data:")
for i in range(dummy_iters):
dummy = next(example_test_generator.generate())
num_predict = 10
true_print_out = "Actual words: "
pred_print_out = "Predicted words: "
for i in range(num_predict):
data = next(example_test_generator.generate())
prediction = model.predict(data[0])
predict_word = np.argmax(prediction[:, num_steps - 1, :])
true_print_out += reversed_dictionary[test_data[num_steps + dummy_iters + i]] + " "
pred_print_out += reversed_dictionary[predict_word] + " "
print(true_print_out)
print(pred_print_out)
O treinamento dessa rede é pesado, apesar de apenas 50 epochs e o tamanho reduzido do model. Cada época leva quase 4 minutos em uma GTX1050 Ti em um Dell Gaming, o que dá mais de 4 horas rodando direto. Se for fazer na CPU, provavelmente vai um dia. Por isso, interrompi durante o décimo segundo epoch, o que é bem pouco, mas deu pra testar. A predição ficou horrível com tão pouco treinamento, nem vale a pena, mas vou mostrar o resultado para te motivar a deixar completar a tarefa:



Depois de treinado, podemos fazer testes com os diferentes models salvos:
python keras_lstm.py -r 2 -p /home/djames/neuralNetworks/RNN/simple-examples/data/ -m model-11.hdf5
Por enquanto é isso, vou escrever um outro tutorial mais atrativo nos resultados, o importante desse era mesmo os conceitos.
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.