




Manual
do
Maker
.
com
Multithread no Raspberry com C++



Esse é o terceiro artigo de dicas para programar em C++ no Raspberry. Essa série de tutoriais tem o intuito de mostrar recursos que normalmente são desconhecidos para quem não programa em x86 ou em plataformas embarcadas com sistema operacional (foge à regra RTOS, que utiliza tasks, como pode ser visto nos tutoriais de ESP32). Hoje veremos como fazer execução "paralela", para executar funções de código de forma assíncrona, utilizando multithread no Raspberry Pi. O primeiro artigo da série pode ser visto aqui, o segundo aqui.
Execução "paralela"
Não existe realmente execução paralela, mas não vamos entrar nos detalhes sobre esse assunto porque é bastante complexo. Apenas vamos ter em mente que as tarefas são executadas de forma concorrente e sequencial. Essa execução é abstraída para o programador, sendo o sistema operacional responsável por fazer o escalonamento de processos.
Execução paralela pode acontecer no caso de múltiplos núcleos, mas nesse caso é como se fossem vários computadores, onde cada processador se encarrega em fazer seu escalonamento. Ainda assim, existe concorrência.
Interrupções em microcontroladoras
Algumas pessoas fazem um pouco de confusão com isso. Quando tratamos interrupções em microcontroladoras, estamos saindo do fluxo principal e atendendo a interrupção. Depois disso, a tarefa principal é retomada do ponto em que foi paralisada.
Dá pra fazer um ótimo controle em MCUs com interrupção, algumas até tem diversos níveis de interrupção, mas não é a mesma coisa que uma thread ou nem mesmo uma task.
Preempção
Em sistemas operacionais preemptivos, várias tarefas podem estar em execução em um determinado intervalo de tempo, alternando entre sí a utilização de recursos. Isso é algo como round-robin nas tasks do ESP32.
Os estados de uma tarefa podem ser nova, pronta, executando, suspensa e terminada. Mais uma vez, a melhor maneira de ver e interagir com isso é no ESP32 (em um sistema operacional de tempo real, mas aqui no blog você encontra exemplos com ESP32).
Processos
Focando já em Raspberry Pi, temos um sistema operacional "tradicional", com um kernel modular, sistemas de arquivos, sistema raiz etc. A grande diferença em programar para um Linux no Raspberry e um Linux desktop está na arquitetura, que no Raspberry é ARM. Normalmente temos em desktops/notebooks uma arquitetura x86 ou AMD64. Apenas para esclarecer, x86 é uma arquitetura criada pela IBM, utilizada pelos fabricantes de processadores como Intel e AMD. Já o AMD64 é arquitetura desktop de 64bits, criada pela AMD, por isso a arquitetura leva seu nome, ainda que, seja um Intel 64 bits - salvo o Itanium, que é um processador de 64 bits criado para servidores. E durante um bom tempo, logo no início dos processadores 64 bits, muitas pessoas compilavam o kernel para IA64, mas IA64 é o Itanium e as pessoas pensavam se tratar de Intel/Amd 64, quando na verdade deveriam estar compilando o kernel com arquitetura AMD64. Acho que não preciso citar o resultado; o sistema não iniciava, claro.
Enfim, tudo isso para falar que um processo é qualquer porção de código que esteja em execução em um sistema operacional. Ele gera um PID (Process IDentifier - não confundir com Proporcional Integral Derivativa) e no Linux esses PIDs podem ser consultados em um bom formato através do comando ps ax. Podemos controlar esses processos criando serviços de sistema, agendando sua execução através do agendador de tarefas do Linux (cron) ou executando e interrompendo através de um terminal (seja através do kill, pkill ou Ctrl+C (se o processo estiver sendo executado em foreground).
Para os processos se comunicarem entre si, devemos usar algum tipo de IPC, seja DBUS, socket, shared memory (utilizando por exemplo o próprio dispositivo de sistema de arquivos em memória, o /dev/shm), arquivos descritores de pipe (mkpipe para criá-los) ou UNIX sockets.
Esse comportamento é desejável quando programas diferentes precisam trocar informações, mas claro, existem outros meios de fazê-lo, como utilizando a camada TCP/IP (com um broker MQTT local, por exemplo).
Thread
Já vimos que um processo é um programa e a execução de um programa gera um PID no sistema operacional. Também vimos que podemos fazer IPC (Inter Process Communication) de diversas formas, portanto poderíamos ter várias instâncias de um programa em execução, ou várias partes de um sistema rodando e se comunicando entre si. Porém, em muitos casos podemos (e até devemos) utilizar o recurso chamado thread, que é a execução assíncrona de uma porção de código do nosso programa principal. E aí acredito que consegui figurar um pouco do poder de uma plataforma embarcada com sistema operacional; as possibilidades são ilimitadas!
Existem threads criadas pelo usuário e as threads criadas (ou executadas) pelo kernel, sendo denominados como user space e kernel space. Aqui vamos ver como criar threads no user space.
Existem diversos outros conceitos envolvidos, além dos estados temos também a pilha, memória compartilhada, processo pai, processo filho etc. Vou tentar apenas mostrar a criação de threads em C++ para ficar claro como funciona, mas a aplicação adequada dependerá de sua visão sobre a necessidade do seu programa. Multithread no Raspberry não difere das demais plataformas nesse aspecto.
Multithread no Raspberry
Agora vamos escrever um pouco de código.
Podemos escrever threads em C++ utilizando a biblioteca pthread diretamente ou então através do Qt (que é um framework para C++), utilizando a Qthread, signal/slot ou outra. Com o Qt também podemos criar processos de terminal, o problema é que o programa fica grande e diversas dependências são somadas ao programa principal. Pode não ser mal, avaliando o custo/benefício; será mais rápido desenvolver? Os recursos de sistema são limitados demais para fazer uso do framework?
pthread
Em nosso exemplo faremos uso da pthread para fazer multithread no Raspberry. Nem ela, nem QThread são recursos nativos da linguagem. Na verdade, esse recurso é provido pelo sistema operacional. Como o tutorial é para Raspberry e também só uso Linux, utilizaremos essa biblioteca para gerar as threads POSIX.
Sua utilização é bastante simples:
#include <pthread.h>
pthread_create (thread, attr, routine, arg)
Os parâmetros são um identificador para a nova thread, um atributo (que utilizaremos NULL), uma rotina para ser executada e o argumento, que deve ser passado como um ponteiro do tipo void. Posteriormente se faz o casting e para passar diversos parâmetros, utilizamos uma struct.
Código simples
Da mesma forma que em um ESP32, podemos terminar uma thread como se finaliza uma task, seja pela própria thread ou através do código principal. O que não devemos fazer é sair da thread sem um controle.
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_OF_THREADS 5
void *PrintT(void *t_id) {
long tid;
tid = (long)t_id;
cout << "Thread ID: " << tid << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_OF_THREADS];
int rc;
for(uint8_t i = 0; i < NUM_OF_THREADS; i++ ) {
cout << "main() : criando thread numero " << (int) i << endl;
rc = pthread_create(&threads[i], NULL, PrintT, (void *)i);
if (rc) {
cout << "erro ao criar thread: " << (int)rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}
Para compilar, devemos passar a biblioteca com a flag -l. Por exemplo:


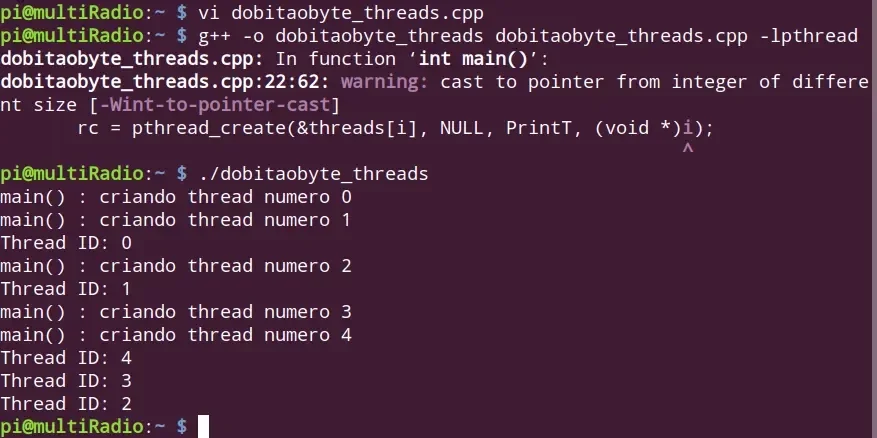
Na imagem acima podemos ver a execução assíncrona, pois não está imprimindo o resultado na sequência.
Passando parâmetros
Como citei anteriormente, podemos passar parâmetros como ponteiro e do tipo void. Vejamos um exemplo, baseado no código anterior.
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_OF_THREADS 5
struct param_example{
char numbers[5] = {'a','b','c','d','e'};
uint8_t pos = 0;
};
void *PrintT(void *t_id) {
struct param_example *tid;
tid = (struct param_example*) t_id;
cout << "Thread ID: " << (int) tid->pos << endl;
cout << tid->numbers[tid->pos] << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_OF_THREADS];
struct param_example td;
int rc;
for(uint8_t i = 0; i < NUM_OF_THREADS; i++ ) {
cout << "main() : criando thread numero " << (int) i << endl;
td.pos = i;
rc = pthread_create(&threads[i], NULL, PrintT, &td);
if (rc) {
cout << "erro ao criar thread: " << (int)rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}
Compilamos novamente e ao executar:


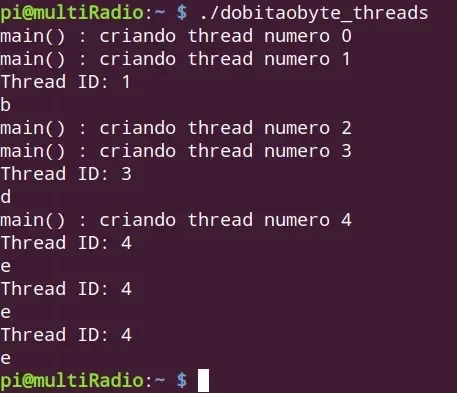
"Ih, deu bug" - você pode pensar. Mas não, está certinho.O que aconteceu é que a thread se executou tardiamente na posição 0, quando a thread 1 já estava sendo iniciada e o valor de i foi modificada no código em main(). Depois, tivemos a mesma condição na posição 2, por isso não vemos o caracter c e então temos 3 vezes o valor da última posição, que foi quando já não havia mais incremento de i.
Serviu perfeitamente para mostrar a execução assíncrona de multithread no Raspberry. Poderia ter controlado isso de outras maneiras, por exemplo, passando uma cópia da struct para cada thread, ou criando um lock com mutex, mas isso e os conceitos relacionados deixarei para um próximo artigo.
Outra coisa importante a considerar é que nesse exemplo apenas a função main() manipulava dados da struct, mas se os dados forem manipulados pela thread, é fundamental haver um controle para evitar colisão no acesso à variável compartilhada. Normalmente, utilizando uma thread, uma fila ou um semáforo, então a manipulação é feita através de uma chamada de função.
Espero que esteja se interessando pelo conteúdo e veremos aplicações em artigos futuros. De qualquer modo, era fundamental escrever essa introdução.
Onde comprar Raspberry?
Minha recomendação é que a Raspberry seja adquirida com nosso parceiro CurtoCircuito. Compra segura, entrega rápida e confiável.
Aproveite para ver a linha de sensores e ESP32, é excepcional!
Até a próxima
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.