




Manual
do
Maker
.
com
Microfone I2S com Raspberry Pi



Invés de ESP32, dessa vez vamos ver como configurar o microfone i2s com Raspberry Pi. Será o mesmo microfone omnidirecional desse artigo. Como disso, falta fazer ajustes de som para o ESP32, como você pode ver nesse vídeo, mas com Raspberry a história é outra.
Barramento I2S
O barramento I2S ("I squared S" ) é o conhecido barramento "inter-IC sound", que é um pouco mais elaborado do que os tradicionais barramentos seriais que utilizamos tão frequentemente. Esses microfones são conhecidos como "MEMS microphones", cujo acrônimo não encontrei definição graças à prioridade dada pelo google à palavra "MEMES".
Para facilitar ainda mais, vamos fazer a comunicação utilizando Python, mas devemos preceder a implementação com a configuração do Raspberry para habilitar o barramento I2S.
Habilitando microfone I2S com Raspberry Pi
Os passos descritos devem ser seguidos à risca para que funcione. A instalação do sistema segue o método padrão. Se não sabe como fazê-lo ou quer ver outros métodos, confira esse vídeo. O procedimento é descrito para Linux e Windows.
Atualize o sistema
O sistema deve estar atualizado. Garanta isso, abrindo um termina e digitando os seguintes comandos:
sudo su
apt-get -y update
apt-get -y upgrade
shutdown -r now
O último comando reiniciará o Raspberry. Se não conhecia o comando, não se assuste ao ver o sistema apagando.
Se estiver com a swap habilitada, desabilite-a para poupar seu micro-sd:
sudo su
swapoff -a
dphys-swapfile swapoff
cd /etc/rc5.d && unlink S01dphys-swapfile
sudo update-rc.d dphys-swapfile disable
Se quiser mais dicas para aumentar a vida útil do seu micro SD, veja esse artigo.
Preparando o ambiente: Python e módulo I2S
O ambiente tem que ser Python3, pois o 2.7 foi descontinuado há algum tempo. Precisamos do Python pip e alguma interface de programação. A interface de programação pode ser local ou remota, pode ser o IDLE ou o vscode. São muitissíssimas as possibilidades, das quais não poderei explanar todas nesse artigo. Partamos da premissa que tudo será feito diretamente no Raspberry.
Instale o pip e a IDE que preferir. Por exemplo, vscode:
sudo su
apt-get install -y python3-pip code
Agora o shell python da Adafruit:
pip3 install --upgrade adafruit-python-shell
E por fim, baixamos o script python para configurar nosso microfone:
wget https://raw.githubusercontent.com/adafruit/Raspberry-Pi-Installer-Scripts/master/i2smic.py
Agora executamos o script, que nos guiará no processo.
python3 i2smic.py
Isso resultará nessa mensagem no prompt, a qual confirmaremos com 'y' para iniciar o módulo I2S no boot do sistema.


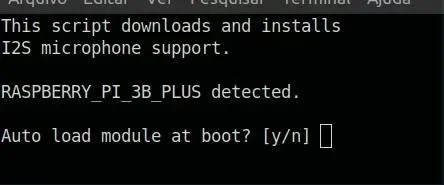
Depois de compilado o módulo, será solicitado o reboot. Confirme com 'y' ou simplesmente aperte Enter, já que a opção estará com Y maiúsculo, o que significa que é a opção padrão.
Para análises, vamos instalar mais uma série de pacotes - não essenciais, mas vi um exemplo que me interessou. Se lhe interessa também, faça o seguinte:
sudo su
apt-get install libportaudio0 libportaudio2 libportaudiocpp0 portaudio19-dev
pip3 install pyaudio matplotlib scipy
"Diz a lenda" para reiniciar, mas exceto se esteja instalando um módulo a ser carregado no boot, não vejo razão para reiniciar. Mas considerando que já disparamos uma rajada de reboots, um a mais não fará mal.
Virtualenv com Python
Uma ótima maneira de não deixar "bagunça" no sistema é utilizar o virtualenv. Com ele criamos nosso ambiente de desenvolvimento para um projeto específico e, quando não mais necessário, descartamos o ambiente, sem deixar resíduos no sistema operacional. Se desejar instalá-lo, use o seguinte comando:
apt-get install virtualenv virtualenvwrapper
Depois, crie um ambiente para o microfone:
virtualenv microfone -p python3
E habilite o ambiente, que deverá aparecer no prompt:
source microfone/bin/activate
O resultado será esse até aqui:



Quando quiser sair do virtualenv, digite:
deactivate
Agora que temos um ambiente virtual que comportará tudo o que queremos, podemos aproveitar para instalar um programador em fluxo; o bpython:
pip3 install bpython
Estando no virtualenv, será necessário instalar o módulo pyaudio:
pip3 install pyaudio
Agora podemos abrir o bpython no console e digitar:
import pyaudio
audio = pyaudio.PyAudio()
for ii in range(0,audio.get_device_count()):
# print out device info
print(audio.get_device_info_by_index(ii))
Ainda não conectei o microfone ao Raspberry, mas já pude testar o código até aqui.


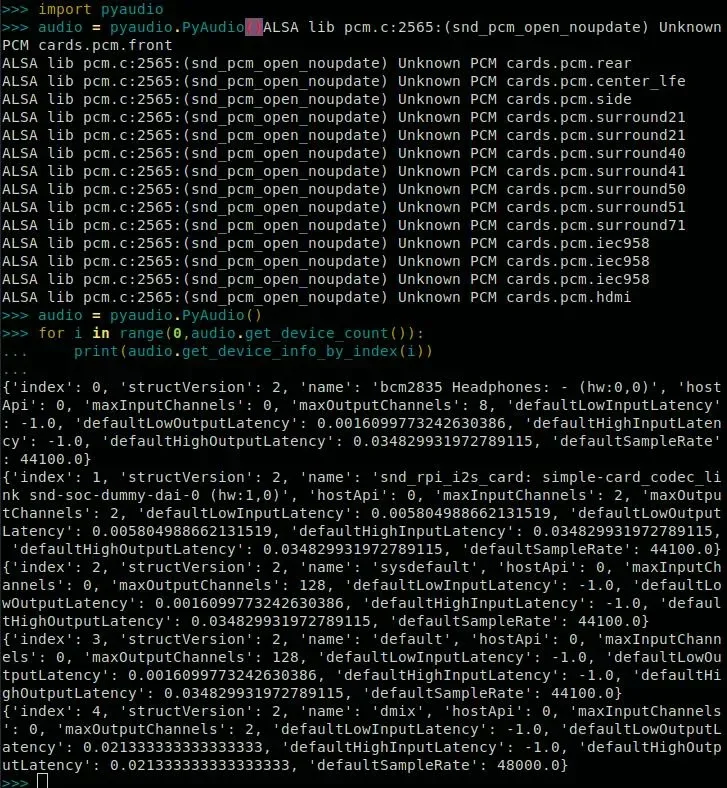
T E M que aparecer em algum dos dicionários o valor de name como snd_rpi_i2s_card. Se apareceu, aplausos! Passe para a próxima fase, lembrando de anotar o index em que aparece a placa, pra colocar na variável pertinente. Tendo localizado o respectivo index, adicione-o em dev_index, lá pra linha 182. No meu caso, o index foi o 1. Se não colocar o certo, vai dar erro.
Raspberry Pi INMP441 MEMS pinout
Hora de fazer o pinout. Desligue o Raspberry Pi para não fazer besteira, então siga o pinout pela imagem Ctrl+Chups que fiz nessa pesquisa.


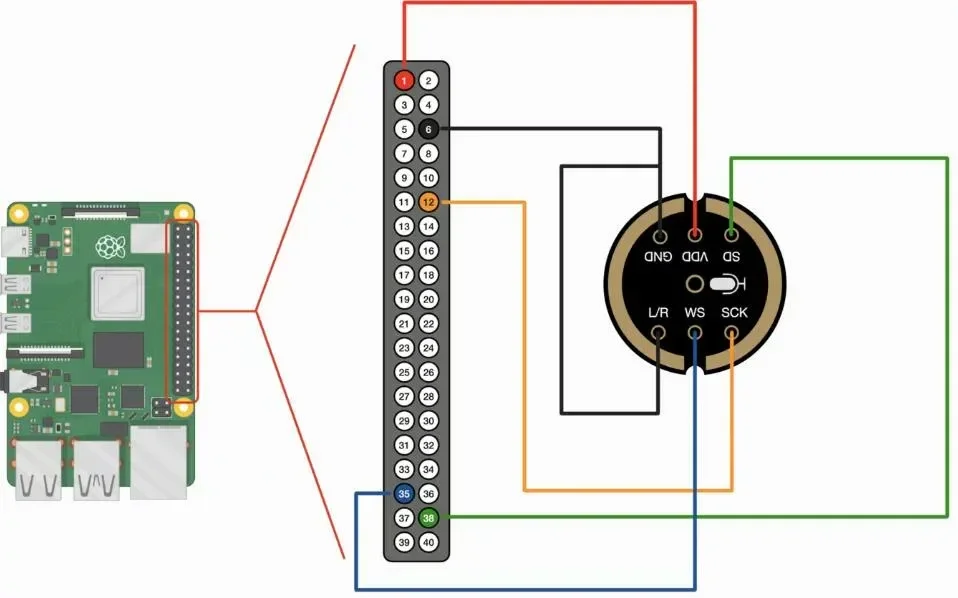
Ligue o Raspberry. Não havendo sinal de fumaça nem vaga-lumes infernais, siga feliz para o próximo passo.
Código inicial para o microfone I2S com Raspberry
Esse código foi criado integralmente por Josh Hrisko. Resumidamente, os tutoriais que existem se baseiam na implementação inicial da Adafruit, que criou um excelente suporte, como disposto mais acima. Porém esse código tem um trabalho extra, no qual implementei exclusivamente a parametrização por linha de comando, que discorro mais adiante.
Dos recursos implementados por Josh, temos 1 segundo de gravação de ruído, 5 segundos de dados em 44KHz, geração de arquivo .wav, remoção de ruído, seleção de frequência de pico com transformada rápida de Fourier e plot da gravação. Mantive os padrões na ausência dos parâmetros, porém as variações poderão ser feitas por linha de comando.
Se estiver utilizando virtualenv, instale também algumas dependências:
pip3 install matplotlib
apt-get install libatlas-base-dev libopenjp2-7 libtiff5
Salve o código do microfone I2S com Raspberry abaixo em um arquivo. Aqui chamei de micTest.py:
##############################################
# INMP441 MEMS Microphone + I2S Module
##############################################
#
# -- Frequency analysis with FFTs and saving
# -- .wav files of MEMS mic recording
#
# --------------------------------------------
# -- by Josh Hrisko, Maker Portal LLC
# --------------------------------------------
#
##############################################
#
import pyaudio
import matplotlib.pyplot as plt
import numpy as np
import time,wave,datetime,os,csv
##############################################
# function for FFT
##############################################
#
def fft_calc(data_vec):
data_vec = data_vec*np.hanning(len(data_vec)) # hanning window
N_fft = len(data_vec) # length of fft
freq_vec = (float(samp_rate)*np.arange(0,int(N_fft/2)))/N_fft # fft frequency vector
fft_data_raw = np.abs(np.fft.fft(data_vec)) # calculate FFT
fft_data = fft_data_raw[0:int(N_fft/2)]/float(N_fft) # FFT amplitude scaling
fft_data[1:] = 2.0*fft_data[1:] # single-sided FFT amplitude doubling
return freq_vec,fft_data
#
##############################################
# function for setting up pyserial
##############################################
#
def pyserial_start():
audio = pyaudio.PyAudio() # create pyaudio instantiation
##############################
### create pyaudio stream ###
# -- streaming can be broken down as follows:
# -- -- format = bit depth of audio recording (16-bit is standard)
# -- -- rate = Sample Rate (44.1kHz, 48kHz, 96kHz)
# -- -- channels = channels to read (1-2, typically)
# -- -- input_device_index = index of sound device
# -- -- input = True (let pyaudio know you want input)
# -- -- frmaes_per_buffer = chunk to grab and keep in buffer before reading
##############################
stream = audio.open(format = pyaudio_format,rate = samp_rate,channels = chans, input_device_index = dev_index,input = True,frames_per_buffer=CHUNK)
stream.stop_stream() # stop stream to prevent overload
return stream,audio
def pyserial_end():
stream.close() # close the stream
audio.terminate() # close the pyaudio connection
#
##############################################
# function for plotting data
##############################################
#
def plotter(plt_1=0,plt_2=0):
plt.style.use('ggplot')
plt.rcParams.update({'font.size':16})
##########################################
# ---- time series and full-period FFT
if plt_1:
fig,axs = plt.subplots(2,1,figsize=(12,8)) # create figure
ax = axs[0] # top axis: time series
ax.plot(t_vec,data,label='Time Series') # time data
ax.set_xlabel('Time [s]') # x-axis in time
ax.set_ylabel('Amplitude') # y-axis amplitude
ax.legend(loc='upper left')
ax2 = axs[1] # bottom axis: frequency domain
ax2.plot(freq_vec,fft_data,label='Frequency Spectrum')
ax2.set_xscale('log') # log-scale for better visualization
ax2.set_yscale('log') # log-scale for better visualization
ax2.set_xlabel('Frequency [Hz]')# frequency label
ax2.set_ylabel('Amplitude') # amplitude label
ax2.legend(loc='upper left')
# peak finder labeling on the FFT plot
max_indx = np.argmax(fft_data) # FFT peak index
ax2.annotate(r'$f_{max}$'+' = {0:2.1f}Hz'.format(freq_vec[max_indx]),
xy=(freq_vec[max_indx],fft_data[max_indx]),
xytext=(2.0*freq_vec[max_indx],
(fft_data[max_indx]+np.mean(fft_data))/2.0),
arrowprops=dict(facecolor='black',shrink=0.1)) # peak label
##########################################
# ---- spectrogram (FFT vs time)
if plt_2:
fig2,ax3 = plt.subplots(figsize=(12,8)) # second figure
t_spec = np.reshape(np.repeat(t_spectrogram,np.shape(freq_array)[1]),np.shape(freq_array))
y_plot = fft_array # data array
spect = ax3.pcolormesh(t_spec,freq_array,y_plot,shading='nearest') # frequency vs. time/amplitude
ax3.set_ylim([20.0,20000.0])
ax3.set_yscale('log') # logarithmic scale in freq.
cbar = fig2.colorbar(spect) # add colorbar
cbar.ax.set_ylabel('Amplitude',fontsize=16) # amplitude label
fig.subplots_adjust(hspace=0.3)
fig.savefig('I2S_time_series_fft_plot.png',dpi=300,
bbox_inches='tight')
plt.show() # show plot
#
##############################################
# function for grabbing data from buffer
##############################################
#
def data_grabber(rec_len):
stream.start_stream() # start data stream
stream.read(CHUNK,exception_on_overflow=False) # flush port first
t_0 = datetime.datetime.now() # get datetime of recording start
print('Recording Started.')
data,data_frames = [],[] # variables
for frame in range(0,int((samp_rate*rec_len)/CHUNK)):
# grab data frames from buffer
stream_data = stream.read(CHUNK,exception_on_overflow=False)
data_frames.append(stream_data) # append data
data.append(np.frombuffer(stream_data,dtype=buffer_format))
stream.stop_stream() # stop data stream
print('Recording Stopped.')
return data,data_frames,t_0
#
##############################################
# function for analyzing data
##############################################
#
def data_analyzer(chunks_ii):
freq_array,fft_array = [],[]
t_spectrogram = []
data_array = []
t_ii = 0.0
for frame in chunks_ii:
freq_ii,fft_ii = fft_calc(frame) # calculate fft for chunk
freq_array.append(freq_ii) # append chunk freq data to larger array
fft_array.append(fft_ii) # append chunk fft data to larger array
t_vec_ii = np.arange(0,len(frame))/float(samp_rate) # time vector
t_ii+=t_vec_ii[-1]
t_spectrogram.append(t_ii) # time step for time v freq. plot
data_array.extend(frame) # full data array
t_vec = np.arange(0,len(data_array))/samp_rate # time vector for time series
freq_vec,fft_vec = fft_calc(data_array) # fft of entire time series
return t_vec,data_array,freq_vec,fft_vec,freq_array,fft_array,t_spectrogram
#
##############################################
# Save data as .wav file and .csv file
##############################################
#
def data_saver(t_0):
data_folder = './data/' # folder where data will be saved locally
if os.path.isdir(data_folder)==False:
os.mkdir(data_folder) # create folder if it doesn't exist
filename = datetime.datetime.strftime(t_0,
'%Y_%m_%d_%H_%M_%S_pyaudio') # filename based on recording time
wf = wave.open(data_folder+filename+'.wav','wb') # open .wav file for saving
wf.setnchannels(chans) # set channels in .wav file
wf.setsampwidth(audio.get_sample_size(pyaudio_format)) # set bit depth in .wav file
wf.setframerate(samp_rate) # set sample rate in .wav file
wf.writeframes(b''.join(data_frames)) # write frames in .wav file
wf.close() # close .wav file
return filename
#
##############################################
# Main Data Acquisition Procedure
##############################################
#
if __name__=="__main__":
#
###########################
# acquisition parameters
###########################
#
CHUNK = 44100 # frames to keep in buffer between reads
samp_rate = 44100 # sample rate [Hz]
pyaudio_format = pyaudio.paInt16 # 16-bit device
buffer_format = np.int16 # 16-bit for buffer
chans = 1 # only read 1 channel
dev_index = 1 # index of sound device
#
#############################
# stream info and data saver
#############################
#
stream,audio = pyserial_start() # start the pyaudio stream
record_length = 5 # seconds to record
input('Press Enter to Record Noise (Keep Quiet!)')
noise_chunks,_,_ = data_grabber(CHUNK/samp_rate) # grab the data
input('Press Enter to Record Data (Turn Freq. Generator On)')
data_chunks,data_frames,t_0 = data_grabber(record_length) # grab the data
data_saver(t_0) # save the data as a .wav file
pyserial_end() # close the stream/pyaudio connection
#
###########################
# analysis section
###########################
#
_,_,_,fft_noise,_,_,_ = data_analyzer(noise_chunks) # analyze recording
t_vec,data,freq_vec,fft_data,\
freq_array,fft_array,t_spectrogram = data_analyzer(data_chunks) # analyze recording
# below, we're subtracting noise
fft_array = np.subtract(fft_array,fft_noise)
freq_vec = freq_array[0]
fft_data = np.mean(fft_array[1:,:],0)
fft_data = fft_data+np.abs(np.min(fft_data))+1.0
plotter(plt_1=1,plt_2=0) # select which data to plot
# ^(plt_1 is time/freq), ^(plt_2 is spectrogram)
Depois, execute assim:
python3 micTest.py
O programa orientará a fazer 1 segundo de silêncio após apertar Enter. Em seguida ele orientará a fazer a gravação após outro Enter. O arquivo de saída será gerado no diretório data, precedido pelo timestamp. No mesmo nível de diretório em que estiver, também terá o arquivo I2S_time_series_fft_plot.png.


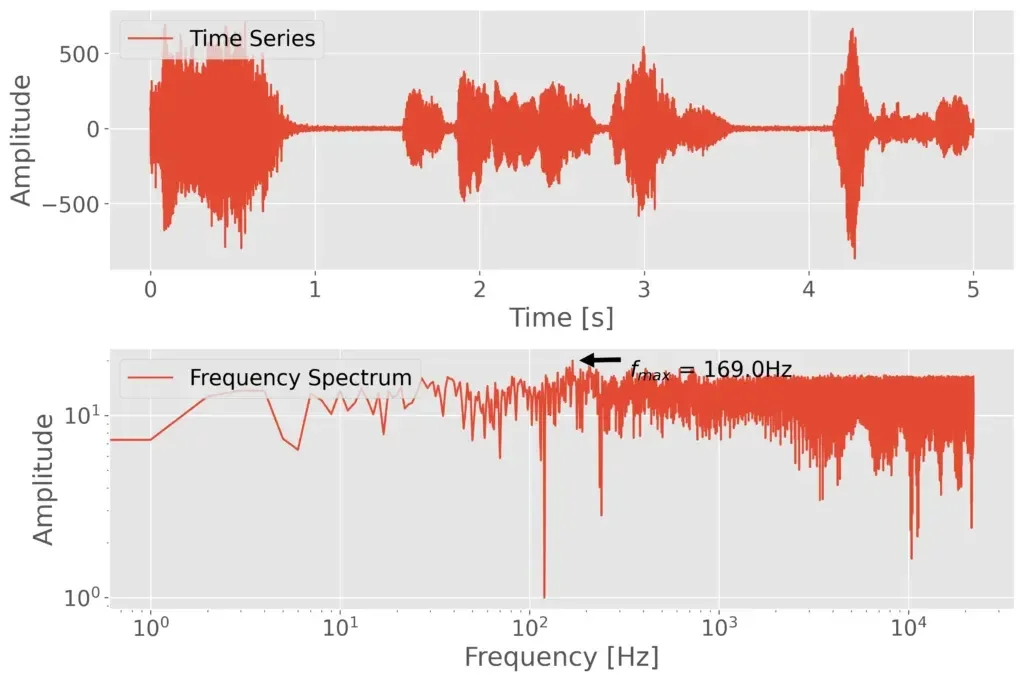


O link para o microfone omnidirecional é esse.
Assim, concluímos a configuração desse microfone I2S com Raspberry, mas a amplitude fico consideravelmente baixa (amplifiquei posteriormente), mas falei a quase 50 centímetros do microfone e o resultado foi surpreendentemente claro, como pode ser visto no vídeo que será publicado tão logo finalize a edição. Aproveite para se inscrever no canal e clique no sininho para receber notificações!
Inscreva-se no nosso canal Manual do Maker no YouTube.
Também estamos no Instagram.



Djames Suhanko
Autor do blog "Do bit Ao Byte / Manual do Maker".
Viciado em embarcados desde 2006.
LinuxUser 158.760, desde 1997.